
Last June, chip-designer Arm released the second-generation Total Compute Solutions roster of technologies built specifically to showcase the potential of premium Android devices that began shipping a few months ago. Designed with eight CPU cores in mind – split between a large, powerful Cortex X3, three mainstream Cortex-A715 and four energy-efficient Cortex-A510 – and optimally tied to in-house Immortalis-G715 graphics, real-world examples of Arm’s work are seen in recent system-on-chips (SoCs) from Qualcomm and MediaTek. Arm’s 2022 technology is therefore present in premium mobile phones such as the Samsung Galaxy S23 Ultra, Xiaomi 13 Pro, One Plus 11, and Vivo X90, amongst others. Though cutting-edge in their own right, Arm is today revealing the hardware blueprint behind the third-generation Total Compute Solutions (TCS23), destined for flagship phones in 2024. Let’s dig in.

Improvements Everywhere
Represented as high-level SoCs, last year’s TCS22 was notable insofar as it dropped 32-bit software support entirely, with the reasoning being the vast majority of popular apps had been ported over to more efficient 64-bit processing. Qualcomm, however, took Arm’s TCS22 CPU design and massaged it into the Snapdragon 8 Gen 2 SoC by adding a 32-bit-compatible A710 in lieu of an A715 core, ostensibly for the Chinese market. Arm understandably ploughs on with 64-bit-only support in TCS23.

The CPU portion of TCS23 sees improvements everywhere, according to the company, with big-core Cortex-X4 offering a substantial boost over its now in-market predecessor. Cortex-A720 and Cortex-A520, meanwhile, focus on reducing precious battery usage whilst delivering similar levels of performance.
Reading between the lines, Arm wants next year’s flagship smartphones to have more bursty power for compute-intensive applications that run best on Cortex-X4. TCS23 infers peak single-thread performance is a clear focus, whereas a number of light-load apps benefit more from efficiency than all-out processing.
Though most physical interpretations will use eight cores split between the three different designs, it’s possible to now build a cluster with 14 cores, up from 12 on the last generation. Such a chip, should it exist and be populated primarily with Cortex-X4s, would make for an interesting desktop and high-performance laptop alternative to incumbent x86.
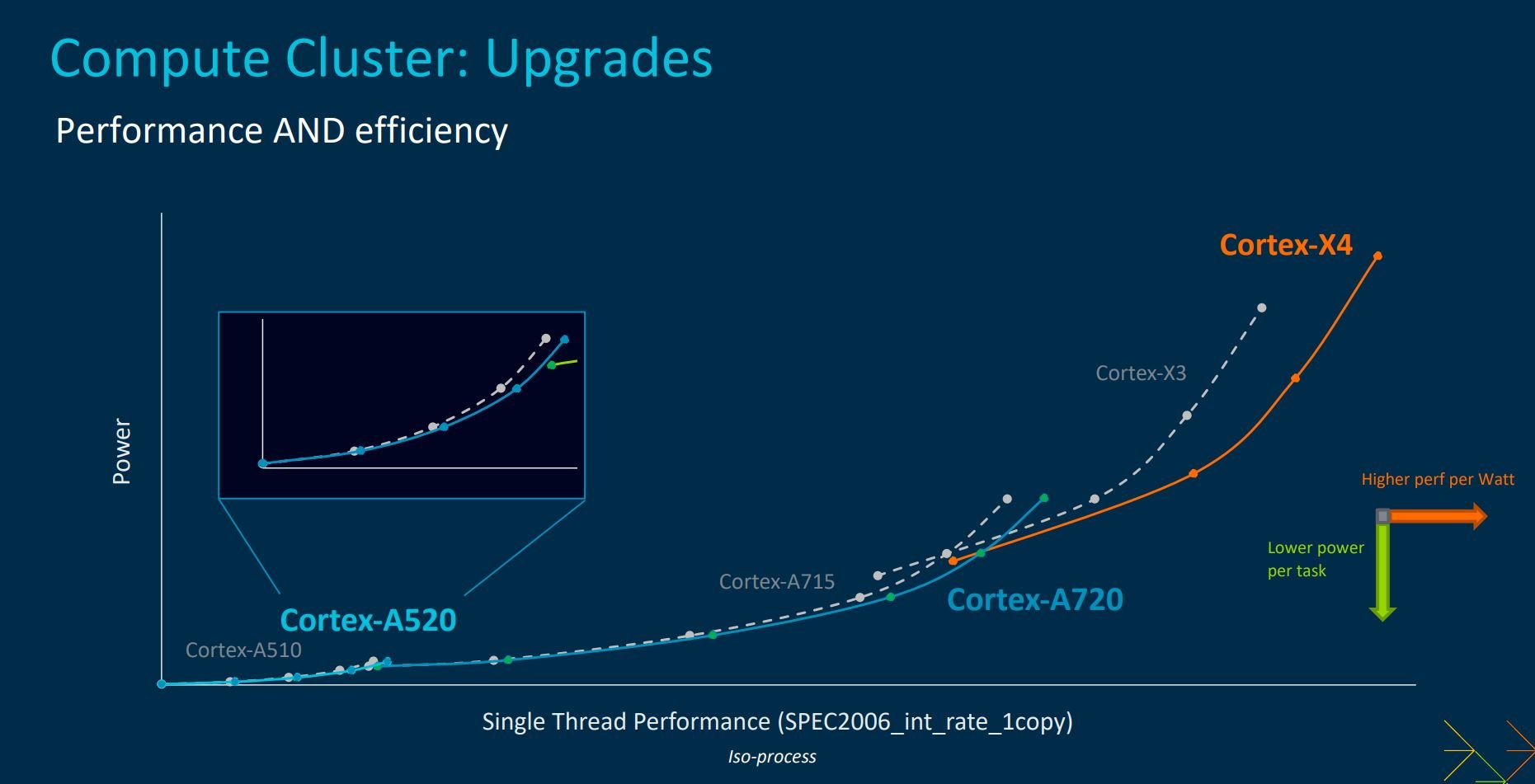
Arm’s CPU strategy is easier to visualise with the above slide. Compared on the same process, you can see low-power Cortex-A520’s blue line sits marginally below that of Cortex-A510. This means that it can deliver an equivalent level of performance at a lower power budget, with most of that gain arriving at its top-end. The story is also true of Cortex-A720 vs. Cortex-A715, so expect incremental jumps when comparing TCS22 and TCS23 SoCs in everyday workloads.
Cortex-X4, as mentioned earlier, is architectetd with performance more to the fore. Notice how, going by Arm’s internal findings, it provides significantly higher oomph or much lower power for a given workload than predecessor Cortex-X3? Each efficiency / performance gain noted above ought to be higher in next year’s flagship devices as Arm reckons most will be produced on TSMC’s 3nm process, as opposed to today’s 4nm.
Cortex-X4 – Doubling Down On IPC

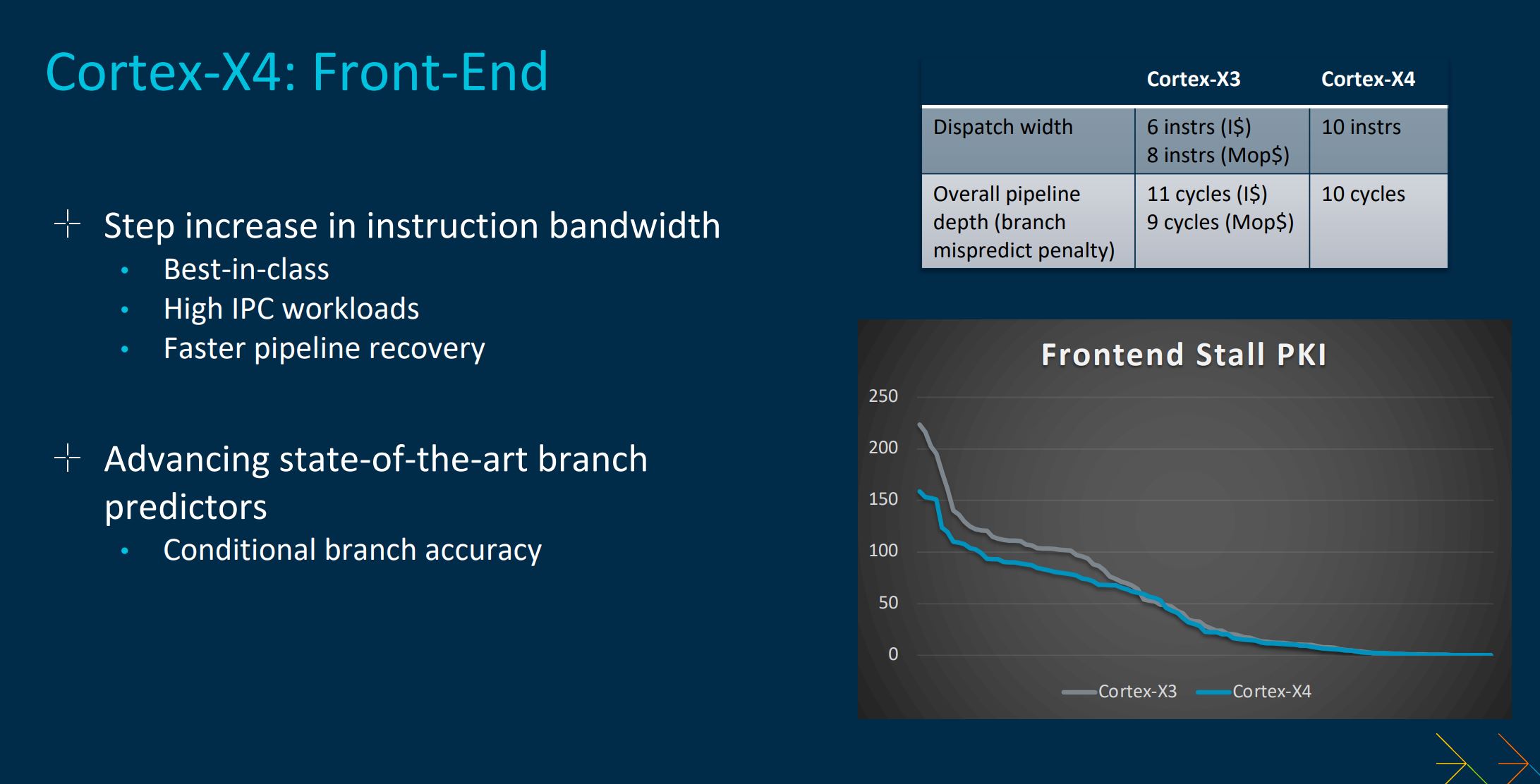
A good question to ask is how Arm has increased Cortex-X4 performance by a healthy degree – the uplift is comfortably larger than from Cortex-X2 to Cortex-X3, we were told at a recent tech day.
Cortex-X-series lead architect, Chris Abernathy, revealed the focus has been on expanding compute capability by making the powerful core better at processing instructions, rather than looking at the branch predictors, as on Cortex-X3. Now offering a 10-wide dispatch and getting rid of the micro-op cache, whilst also reducing the pipeline depth for fewer stalls, Arm also beefs up the chip with more two more ALUs, a further branch unit, larger out-of-order window, and double-sized L1 data TLB. These moves speak to more muscular performance.
The downside of this wider approach is the chip becomes necessarily larger, to the tune of just under 10 per cent when compared with Cortex-X3, though performance uplifts outweigh the size gain. For next year’s SoCs geared for maximum throuput, Arm supports up to 2MB of L2 cache, up from the usual 1MB hitherto attributed to Cortex-X-class.
Cortex-A720 and Cortex-A510 – Primed For Efficiency

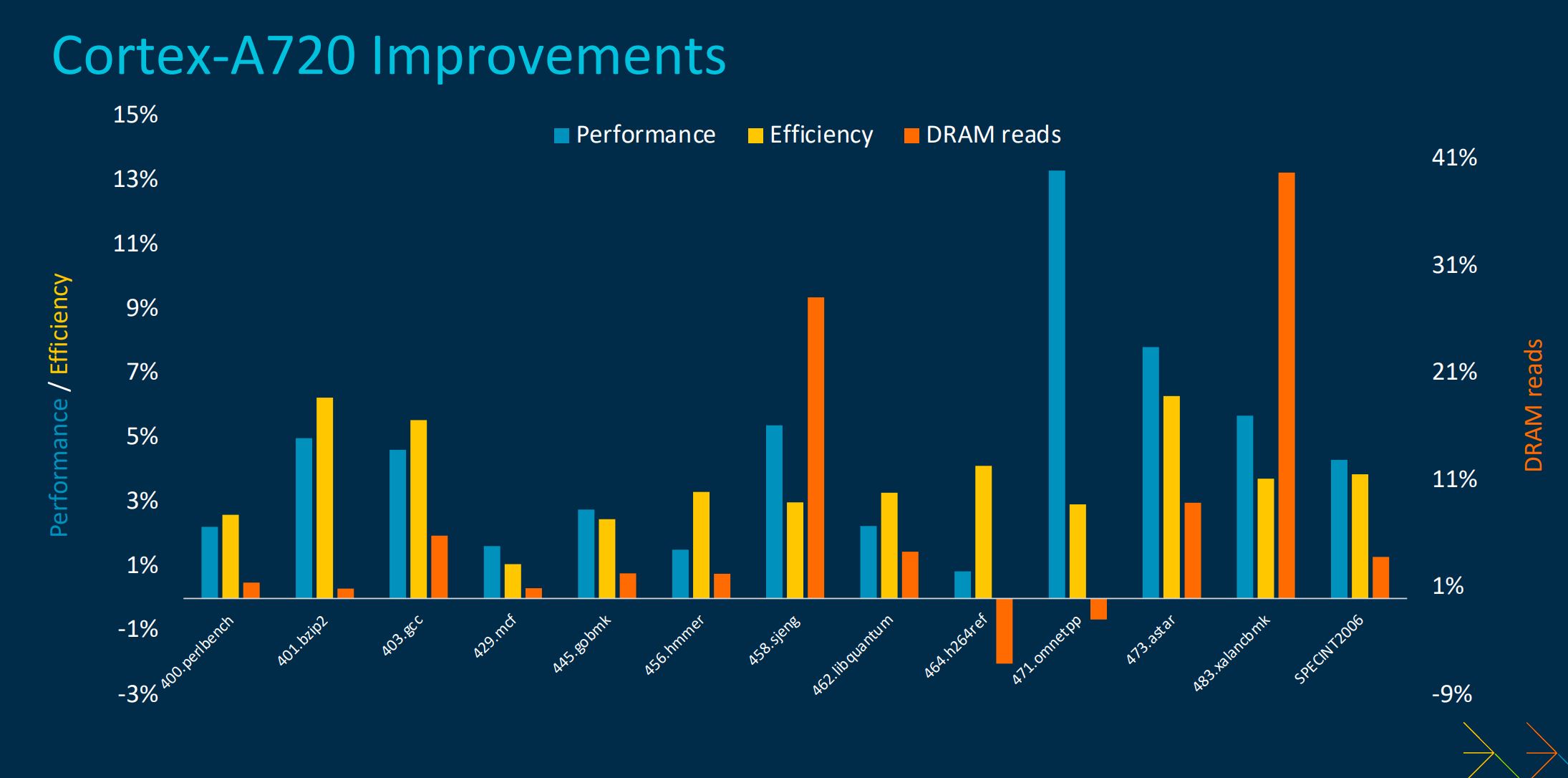
Delivering greater levels of efficiency means there’s no change in the architectural width and depth of Cortex-A720 vs. its immediate predecessor, Cortex-A715. Rather, most of the gains derive from tuning the design by removing bottlenecks that burn power, and the sum of these gains is what sets Cortex-A720 apart.
In particular, Arm removes one cycle from the branch mispredict penalty. May not sound like much, but when the predictor fails in its job due to unusual code, getting back on track quickly is paramount. It’s reasonable to assume Arm has used branch-predictor learnings from the Cortex-A-class and applied them here. Then there are myriad improvements to the out-of-order queue, including better pipelined units, enhanced issue queues and execution units. On the memory side of things, Cortex-A720 removes one cycle of latency for L2 cache hits and improves prefetch accuracy.
This overhaul / tightening, explained Arm’s lead architect, Albin Tonnerre, leads to generous upticks, especially as it pertains to reducing power-intensive DRAM reads. Evolution rather than revolution.

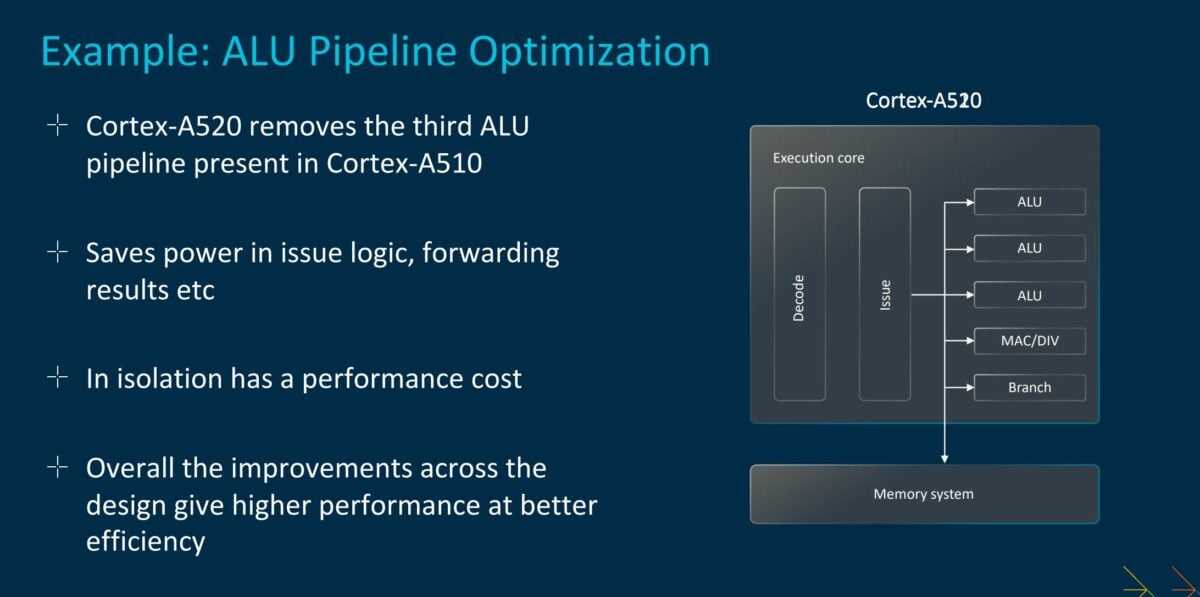
Whereas no major changes are afoot in Cortex-A720, the same cannot be said for Cortex-A520. The focus here is to build the leanest core possible using an efficiency-first designed, explained lead architect, Ian Caulfield. It’s unusual to remove a performance-enhancing feature from a subsequent design, but Arm does exactly this by shelving the third arithmetic logic unit (ALU) this time around.
This third ALU of the previous-gen Cortex-A510 is relatively underused in everyday applications, clearly, so it’s chopping paves the way to save precious area and power. It’s impressive Arm retains Cortex-A510-beating characteristics with this apparent disability in tow, which means the latest small-core design has numerous undisclosed tweaks elsewhere. Arm quotes eight per cent higher performance or 22 per cent lower power at the same level.

Cortex CPUs reside within an overarching cluster known, appropriately enough, as the Dynamic Cluster Unit. TCS23’s sees a natural update that also focusses on efficiency.
Working in many power states according to workload intensity, DSU-120 can opportunistically toggle slice logic that contains L3 and snoop filters. It’s granular, too, as the eight slices provide multiple means by which to turn off power-inducing features.

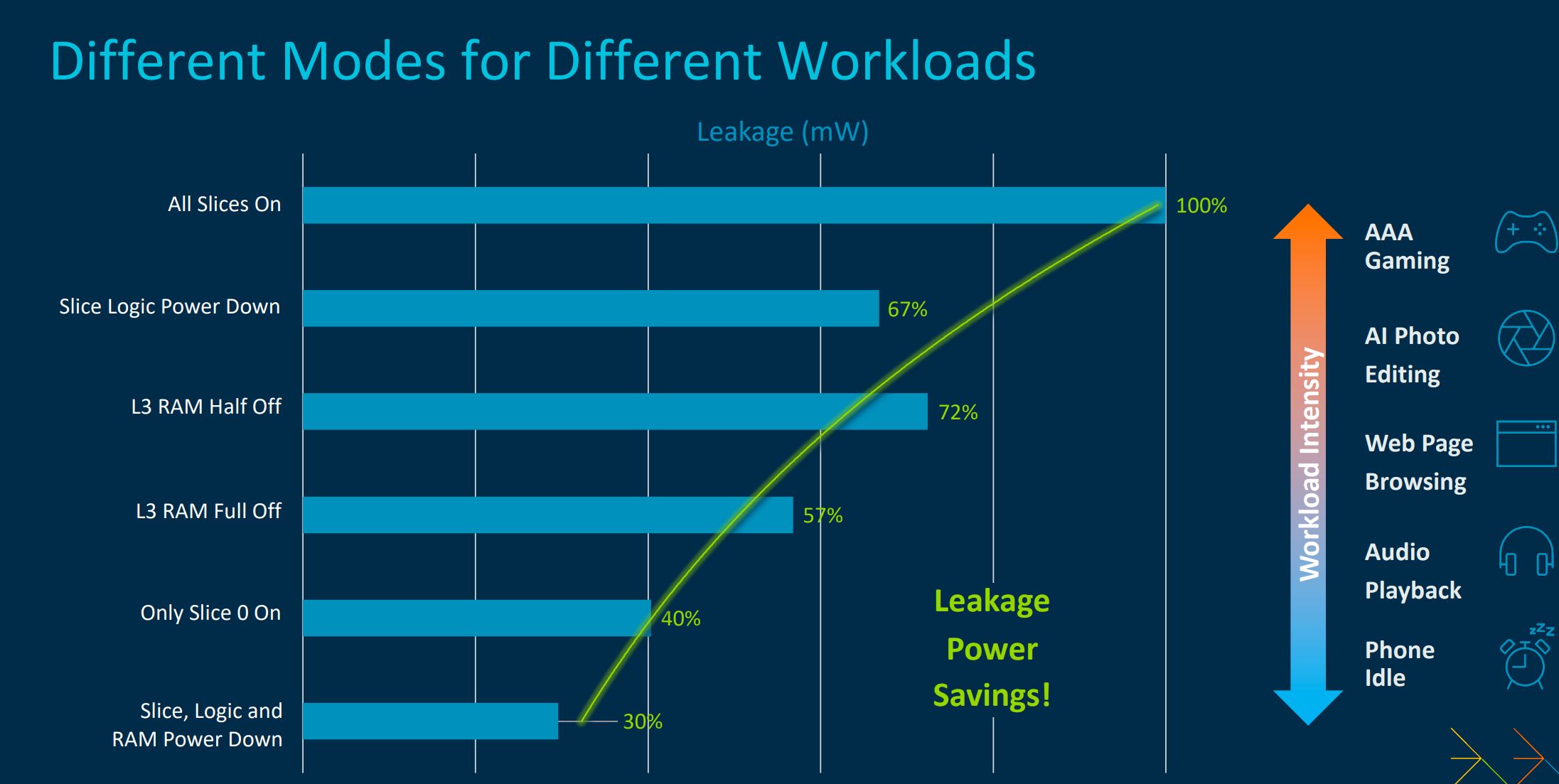
The DSU now supports up to 32MB of L3, split over eight slices, with an option for 24MB, though most flagship phones will carry far less for size and efficiency reasons. Switching off everything possible in the DSU reduces leakage power by around 70 per cent, which is handy for applications that have little need for L3 cache.
The Wrap
Last year’s big focus was on moving Arm’s flagship mobile compute cluster to 64-bit-only processing. This year, performance is geared towards Cortex-X4 whilst energy efficiency is focussed on Cortex-A720 and Cortex-A520. Likely built on TSMC’s 3nm process on actual devices, manufacturers can dial the power savings into other areas of the chip.
Arm’s TCS22 CPU cores tend to lead performance rankings in benchmarks such as AnTuTu, productised mostly with Snapdragon 8 Gen / 2 SoCs, so there’s every reason to think TCS23 will further the advantage over other interpretations such as the A16 Bionic found in premium Apple phones and tablets.
Expect to see TCS23-based flagship mobile phones announced later this year and available early next year, going by recent cadence.