

The high-end PC graphics card industry became a whole heap more interesting when Nvidia brought RTX 40 Series to bear in recent months. It’s no hyperbole to suggest RTX 4090 introduces a step-change in performance, rendering all cards before it meek in comparison.
Rival AMD acutely understands that toppling Big Ada is not achievable this generation and instead frames RDNA 3-powered Radeon RX 7900 XTX ($999, £999.99) and XT ($899, £899.99) GPUs as the absolute best available in the high-volume sub-$1,000 segment. If you can’t beat ’em, reshape the narrative in your favour.


AMD Radeon RX 7900 XTX
£999 / $999
Pros
- GPU chiplets work!
- Solid 4K performance
- Aggressive pricing
- 24GB memory
- DisplayPort 2.1
Cons
- RT not at Nvidia levels
- No frame generation (yet)
Club386 may earn an affiliate commission when you purchase products through links on our site.
How we test and review products.
Radeon RX 7900 XTX and XT are the first two cards powered by RDNA 3 goodness. Before we get to the all-important benchmarks that most enthusiasts gravitate towards, let’s first understand what the latest AMD GPU architecture does for Team Red’s best graphics card.
RDNA 3 – Faster And Smarter
Understanding the impetus behind AMD’s newest GPU architecture first requires an appreciation of two factors affecting the production of cutting-edge silicon. As we move down to ever-smaller nodes, the first is a lack of scaling in two important metrics: memory and analogue I/O, both of which are liberally used in GPU design.
The point here is it’s not worth having these two facets on the latest, most expensive nodes if there is no immediate benefit to doing so, because you’re paying over the odds for no discernible benefit. On the other hand, logic – the building blocks for the core blocks – appears to still scale well, meaning it’s worth investing in smaller processors for attendant gains.
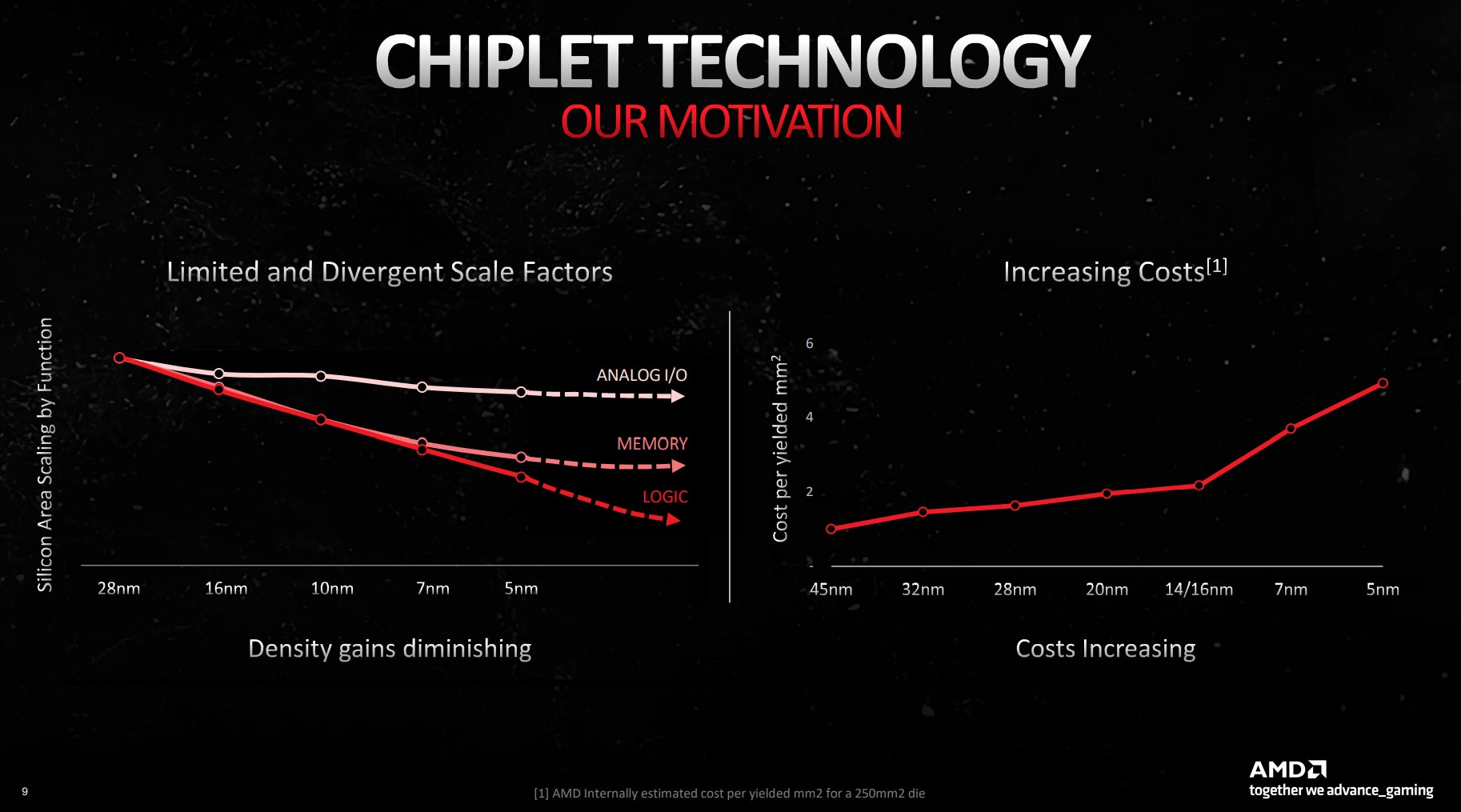
The second point is related to the first insofar as the cost of moving between the latest nodes is becoming significantly more expensive. Only use, say, 5nm production if you absolutely have to, as while it makes powerful chips physically feasible, there comes a time when they’re not financially viable. For example, building a monster, monolithic 700mm² die on purely 5nm is an exercise in inflating end-user cost to arguably unpalatable levels.
a strategy that has worked wonders in the CPU space with chiplet-based Ryzen processors since 2017
Such thinking coalesces into AMD’s fundamental fabrication strategy for high-end graphics moving forwards. Knowing GPUs are essentially huge calculators processing instructions in parallel, why not break down the constituent parts of the design into small blocks, which naturally yield better, and lasso them together with high-speed smarts? It’s a strategy that has worked wonders in the CPU space with chiplet-based Ryzen processors since 2017. But if something was easy, it would have been implemented by now.
GPU Chiplets Provide Unique Challenges
Though brilliant on paper, there are myriad reasons why a chiplet-based GPU is a difficult proposition, exemplified by the graphic below.
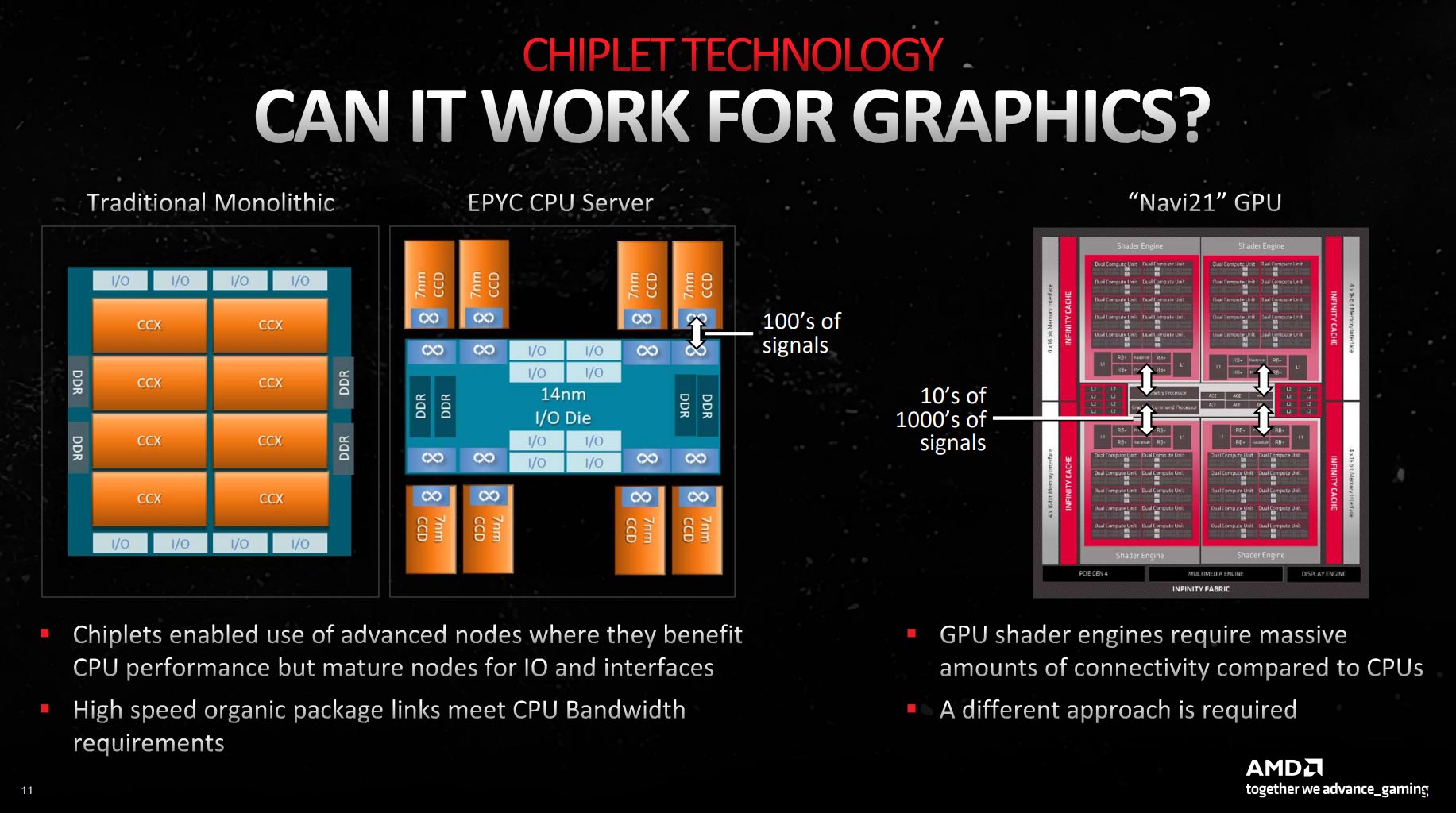
Jumping from a monolithic CPU design to a chiplet-based approach requires invention of high-speed, low-latency interconnects between what are termed Core Complex Dies (CCDs) and a central hub. That link is AMD-developed Infinity Fabric, which connects said chiplets with 100s of wires between dies.
A fantastic feat of engineering, AMD cannot take the same approach when looking at a chiplet-based GPU, and the reason has to do with the massive amounts of data traversing a GPU at any moment. Having upwards of 5,000 cores means the bandwidth required is an order of magnitude higher, and a standard Infinity Fabric approach simply cannot carry that amount of information in a design that has to sell for a set fee to make money.

Putting this problem into intelligible context, AMD estimates a multi-chip GPU needs over 10x the bandwidth offered by the latest Epyc server processors. What to do and how to do it, eh? This is where smart engineering comes to the fore.
AMD’s approach is to flip the problem on its head, and by that we mean build a multi-core chip where the bandwidth-hungry memory partitions are manifested as smaller chiplets while the big computational engines are kept in a larger central die. If you recall, Ryzen processors do the reverse by moving cores to chiplets and memory to the IOD.
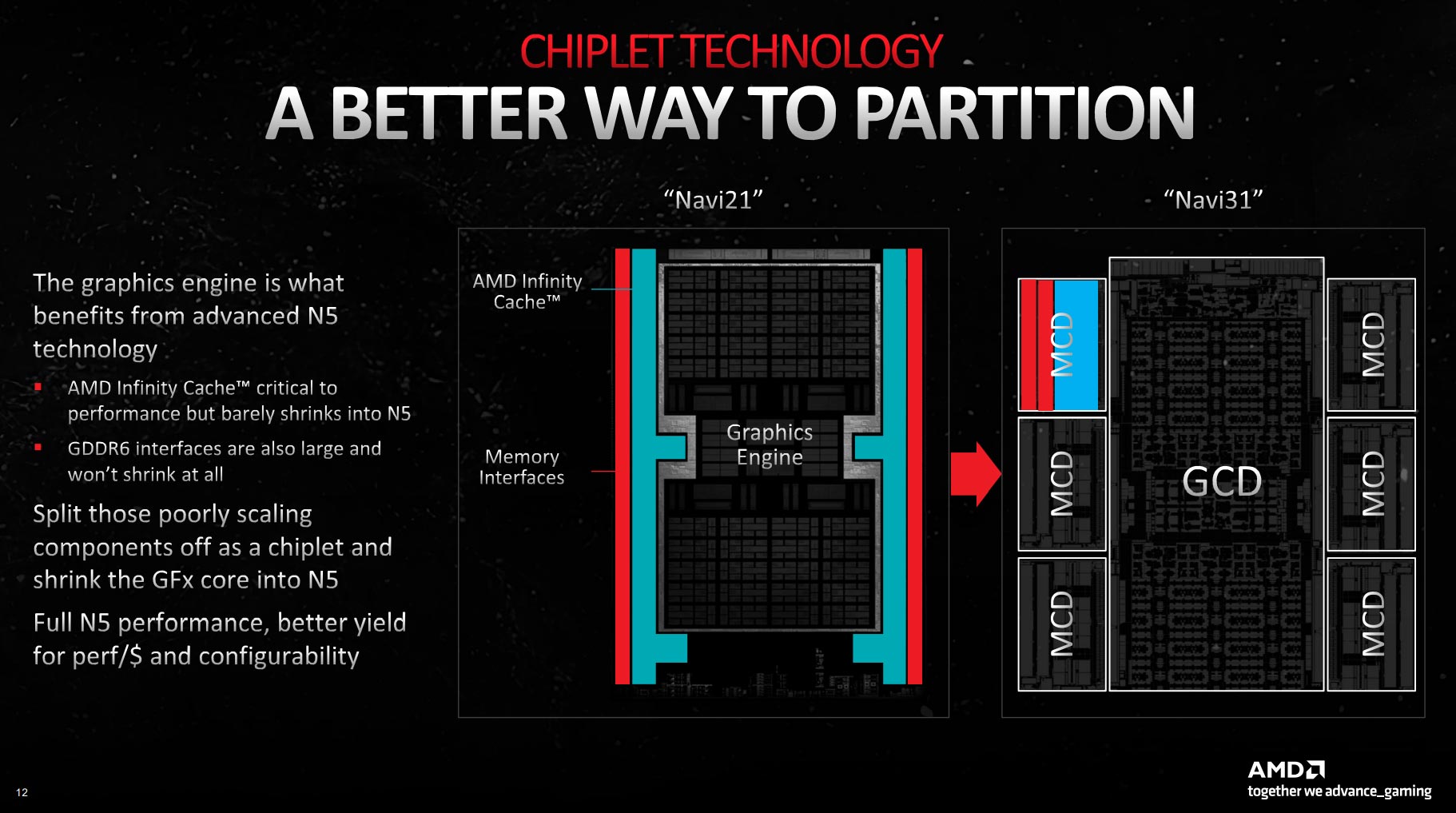
RDNA 3 is therefore built by having multiple Memory Cache Dies (MCDs), fabricated on a 6nm process, circling a larger, 5nm-based Graphics Core Die (GCD). Each MCD carries L3 cache and GDDR6 memory links to the GCD, and accumulating the contents of each MCD provides a good inkling of a card’s memory-side potential.
The GCD meanwhile, and just like Highlander there is only one, is home to familiar Compute Units (CUs) resident with shader cores, ray tracing cores, texture units, and the like.


Linking MCDs to the GCD with the requisite bandwidth is the real triumph for RDNA 3. AMD calls this special sauce Infinity Fabric Fanout Technology (IFFT), illustrated in the slide above. Going by AMD’s presentations, each wire is far, far smaller than its CPU counterpart. If we crunch the numbers, GPU-optimised IFFT is over 50x as dense and provides 10x higher bandwidth than Infinity Fabric On Package (IFOP) used for CPUs. Take a moment for that to sink in.
We needed a new package technology and a new link technology. And that’s what we have implemented.
Sam Naffziger, AMD Senior Vice President and Product Technology Architect
Without IFFT, make no mistake, there is no chiplet-based RDNA 3, as scaling incumbent CPU IFOP technology would result in huge amounts of power diverted solely for the interconnects, let alone any die-space ramifications. Nevertheless, building links between chiplets isn’t a free energy lunch. IFFT takes crucial space and power to perform its high-speed data shuttles at 9.2Gb/s. We estimate adding relevant links, as opposed to a purely monolithic design, increases die area by close to 15 per cent while adding precious watts to overall consumption.
As it is, each TSMC-fabricated 6nm MCD weighs in at around 37mm² and houses some 2bn transistors. That’s a combined 222mm² and 12bn transistors right there for Navi 31 silicon. CU-housing GCD is a significant 300mm², meaning the combined size of the Navi multi-chip GPU is 522mm².
An interesting question arises. Is it better to have a 5nm monolith chip at 450mm² – the size we estimate Navi 31 would be on a single piece of silicon; there would be no space- and power-taking IFFT links – or a multi-chip 5nm/6nm at 522mm²? Not an easy one to answer, and one we’re sure AMD’s bean counters wrestled with.

Another problem facing an IFFT solution is, on paper, one of latency. AMD acknowledges running Infinity Links will always create more latency than conducting transfers within one monolithic die. This issue is shown by the Navi 31 bars marginally higher than Navi 21. However, the combination of a 43 per cent higher IF clock and higher game clock ameliorates the issue. In fact, AMD contends Navi 31 has lower latency… but how much lower could it have been on a monolithic design?
We come away from the chiplet discussion with the thinking that AMD has spent a lot of time and resource in mitigating obvious issues emanating from going down a multi-chip route on a GPU. The pain is worth the long-term benefits, according to AMD, but it seems like a lot of effort.
The chiplet approach ought to play dividends further down the line when we have, say, 12 MCDs surround one or two GCDs. Breaking down the parts into manageable chunks, with presumably better yields than a monolithic monster, is where AMD is aiming. Whether it’s chiplets or tiles, we can foresee Nvidia adopt a similar approach in years to come.
RDNA 3 – Efficiency At The Core

Feast your eyes on that, will you? Having marked off the first part of our discussion, as it pertains to a chiplet design and the whys and wherefores of going down that road, the second is RDNA 3 architecture.
Compared to Navi 21, AMD claims a 54 per cent performance-per-watt increase
It’s hard to miss AMD’s claims of RDNA 3 ‘architected to exceed 3GHz.’ This certainly isn’t the case in the first two cards based on this design, namely Radeon RX 7900 XTX and XT, suggesting AMD hasn’t achieved lofty frequency aspirations in the first retail salvo. A misjudgement of the architecture or relatively poor frequency yields from foundry partner TSMC? Probably a bit of both.
Nevertheless, there is positive news. Compared to Navi 21, which you’ll know as high-end Radeon RX 6000 Series, AMD claims a 54 per cent performance-per-watt increase. That’s nothing to be sniffed at, of course, and the rest of our discussion focusses on how AMD has achieved this number.
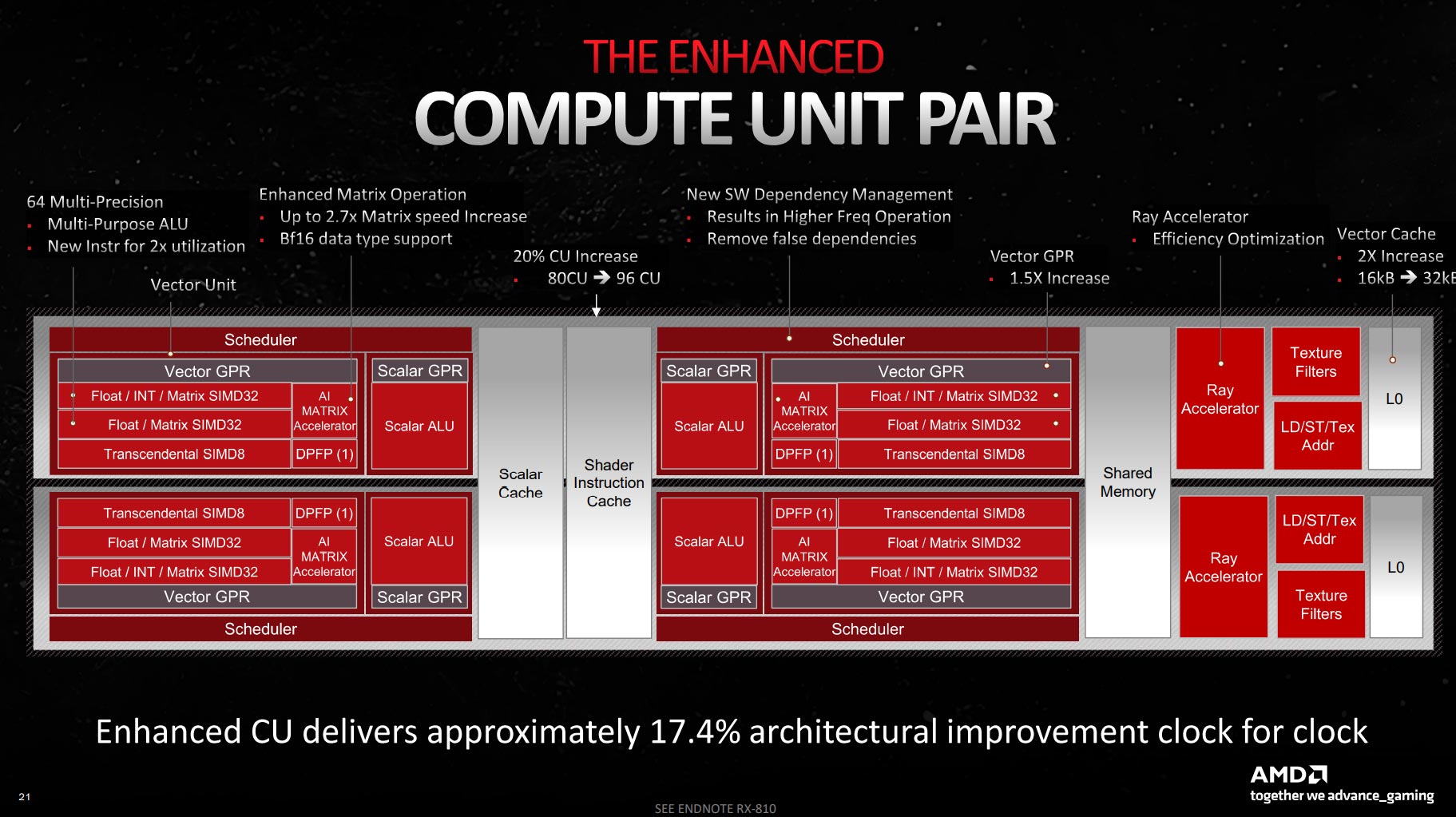
Performance naturally goes up for Navi 31 as it fits in more Compute Units than its immediate predecessor, and the 80CU-96-CU notation gives a 20 per cent boost right off the bat. Shoving in more CUs is entirely expected when moving between architectures and processes. Low-hanging fruit and all that.
Yet the devil is very much in the details. Take another look at the two CU blocks, or pairs. AMD refers to it as a single CU, of which, if you recall, there are 96 in the Big Boy design. But it’s not one CU, is it, as the second is a mirror of the first.
This has important ramifications for performance, and why comparing generation-on-generation is fast bordering on pointless. AMD has effectively doubled each CU’s ALU capability – initialisms, ahoy – meaning there’s double the throughput for floating-point tasks on a shader-to-shader basis.
Breaking it down, each RDNA 3 64-ALU block, or CU, has twice as many FP32 pathways of RDNA 2. Here’s where terminology becomes difficult when referring to ALUs, FP32 units and INT32 units, but suffice to say, FP operations, which are a mainstay of gaming, are much improved.
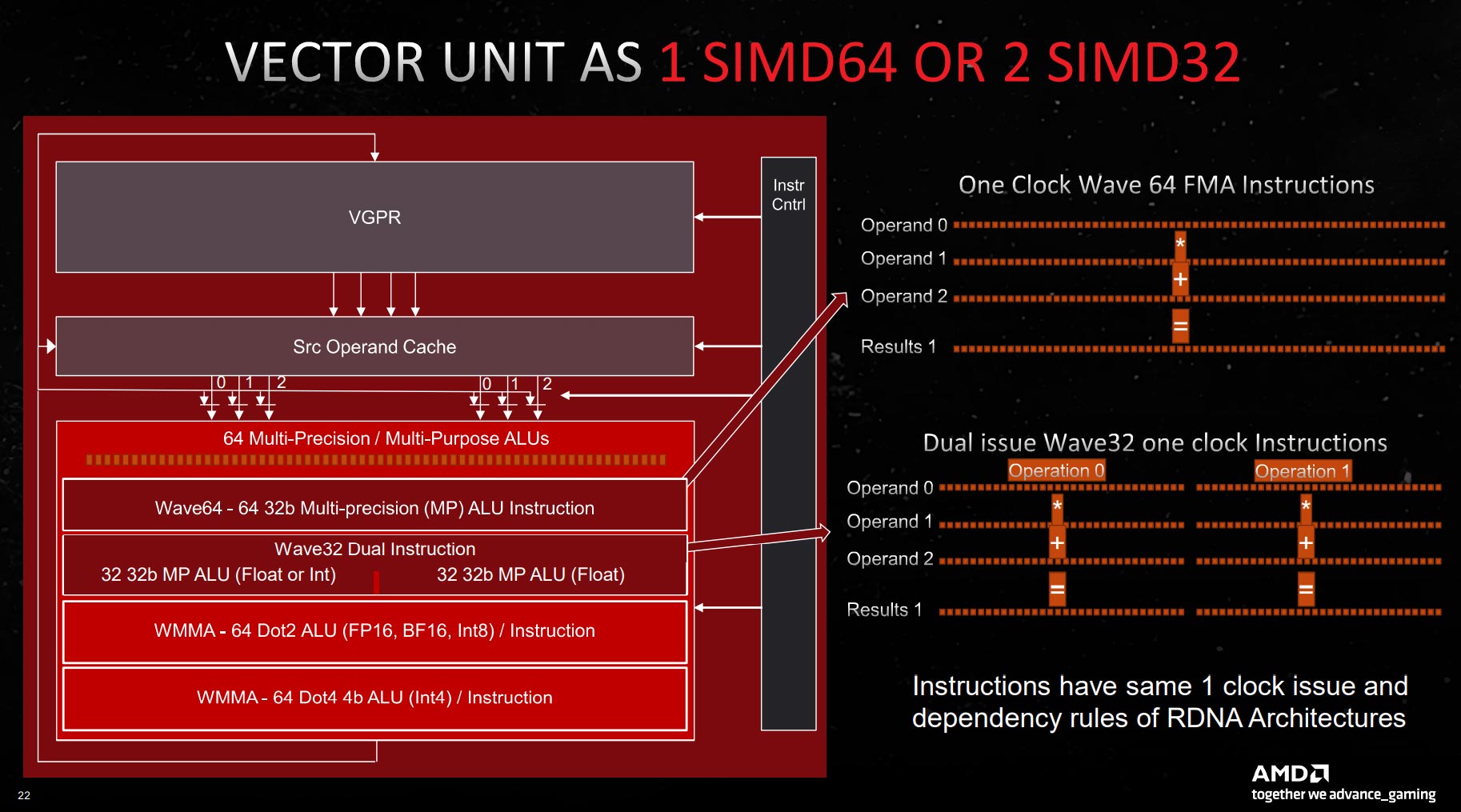
On the integer side, AMD has all-new AI Matrix Accelerators which include bfloat16 and WMMA64 Dot4 support, primarily to help with convolution, which is one of the fundamental operations of deep neural networks with demanding matrix computation. In other words, it is AMD’s answer to Nvidia’s Tensor Cores. Little more is known of the technology other than basic specs and a purported 2.7x matrix speed increase compared to RDNA 2.
Cache Me In

Having a more robust, faster core and memory subsystem helps, but most iterative GPU architectures tend to devote increasing amounts of space for larger caches. Just see what Nvidia did with RTX 40 Series.
Going through the information, it’s easy to see where AMD has doubled sizes compared to RDNA 2. Certainly not the massive increases instigated by Nvidia, yet it stands to reason that caches need to be upgraded to deal with more innate processing power.
The one outlier from this approach is AMD Infinity Cache. Those familiar with how AMD builds recent GPUs will know Radeons have a slab of goodly cache residing between on-chip L2 and external GDDR6. Call it an L3 if you will. RDNA 2’s Infinity Cache topped out at 128MB on Radeon RX 6950 XT. AMD drops it to 96MB for RDNA 3. If larger caches are better and there’s been plenty of increase on L0, L1, and L2, what gives? Good question.
It’s not the size, it’s how you use it, seems to be AMD’s response. Rather than scale this apparent L3 to 128MB+, which takes up valuable real-estate space, AMD has increased the conduit between L2 and Infinity Cache by 2.25x. That’s no small potatoes. Aforementioned RX 6950 XT runs off a 1,024 bytes per clock and has an SoC operating at 1.93GHz achieving total bandwidth of 2TB/s. Navi 31’s best SoC operates at 2.3GHz. Do the math and we reach 5.3TB/s at this juncture alone, without taking the much wider, faster GDDR6 into account.
In that regard, Navi 31 (RX 7900 XTX) has a maximum 384-bit memory bus feeding GDDR6 memory operating at 20Gbps, whereas Navi 21 (RX 6950 XT) is only 256 bits wide and 18Gbps. 576GB/s cannot compete with 960GB/s on today’s champ.
Ray Tracing Overhaul

AMD introduced dedicated hardware ray tracing units in RDNA 2. Yet while rasterisation performance was roughly analogous to price-comparable Nvidia RTX 30 Series, RT lagged behind considerably. The gap has become a chasm with the introduction of RTX 40 Series, so if you want best-in-class lighting, Team Green is the way to go.
Looking to arrest this gulf, AMD has invigorated the RT units within RDNA 3. As RT hardware is tied to CUs on a one-to-one basis, there is more ray tracing potential through sheer numbers – 96 Ray Accelerators vs. 80.
we’d put the best-case RT scenario as one matching premium RTX 30 Series cards
AMD’s focus on RDNA 3 isn’t an entirely new RT unit – that would be too costly to implement at this stage – but one of improving what it has to work with. Part of this rests with efficiency, insofar as not doing work that’s of no use. RDNA 3 introduces an early subtree culling to remove unnecessary calculations by skipping parts of the acceleration structure during traversal.
There are further improvements, too, from having more rays in flight to natural uplifts caused by larger caches, CUs, and so forth, but the bottom line is that combined efforts are no silver bullet; we’re not going to see Nvidia RTX-like numbers anytime soon. In fact, though AMD contends an 80 per cent improvement for RDNA 3 over RDNA 2, we’d put the best-case RT scenario as one matching premium RTX 30 Series cards. RTX 40 Series will remain in a different league.
Bits And Bobs
Head back up and look across to the advancements in the pixel pipe. Complementing the increased top-end muscle, AMD ups ROP count by 50 per cent, from 128 to 192.
We touched on bandwidth hikes earlier, yet it’s prudent to recap. AMD’s Infinity Cache is 165 per cent faster and external memory affords 67 per cent over the previous generation. You gotta feed the CU beast.
On the display side of things, AMD keeps to HDMI 2.1a of the previous generation and adds in DisplayPort 2.1, which is a feature missing on rival Nvidia RTX 40 Series cards.
A Dual Media Engine brings hardware-accelerated support for AV1 encode and decode up to 8K60, among other niceties, and outputs are such that a single card can drive four 4K144 displays.
Enter Radeon RX 7900 XTX and XT
| Radeon | RX 7900 XTX | RX 7900 XT | RX 6950 XT | RX 6800 XT |
|---|---|---|---|---|
| Launch date | Dec 2022 | Dec 2022 | May 2022 | Nov 2020 |
| Codename | Navi 31 | Navi 31 | Navi 21 | Navi 21 |
| Architecture | RDNA 3 | RDNA 3 | RDNA 2 | RDNA 2 |
| Process (nm) | 5/6 | 5/6 | 7 | 7 |
| Transistors (bn) | 57.7 | 57.7 | 26.8 | 26.8 |
| Die size (mm2) | 522 | 522 | 520 | 520 |
| Compute Units | 96 of 96 | 84 of 96 | 80 of 80 | 72 of 80 |
| ALUs | 6,144 | 5,376 | 5,120 | 4,608 |
| Boost clock (MHz) | 2,500 | 2,400 | 2,310 | 2,250 |
| Peak FP32 TFLOPS | 61.44 | 51.61 | 23.65 | 20.74 |
| RT cores | 96 | 84 | 80 | 72 |
| AI cores | 192 | 168 | – | – |
| ROPs | 192 | 192 | 128 | 128 |
| Infinity Cache (MB) | 96 | 80 | 128 | 128 |
| Memory size (GB) | 24 | 20 | 16 | 16 |
| Memory type | GDDR6 | GDDR6 | GDDR6 | GDDR6X |
| Memory bus (bits) | 384 | 320 | 256 | 256 |
| Memory clock (Gbps) | 20 | 20 | 18 | 16 |
| Bandwidth (GB/s) | 960 | 800 | 576 | 512 |
| Power (watts) | 355 | 315 | 335 | 300 |
| Launch MSRP ($) | 999 | 899 | 1,099 | 649 |
All of our discussion has rightfully centred on the overarching RDNA 3 architecture and consequent Navi 31 GPU. Both terms describe the available hardware tools from which AMD constructs retail cards. Those are Radeon RX 7900 XTX and Radeon RX 7900 XT, both hewn from Navi 31, albeit differently.
Starting with the best Radeon to date, RX 7900 XTX uses the full 96-CU complement available on the die – there is no holding back, unlike how Nvidia traditionally keeps cores unused on consumer graphics cards. It’s a big beast, alright, with 57.7bn transistors spread over the six MCDs and GCD. Simple math informs us 12bn of those go towards the former and 45bn to the cores.
Depending on how one defines ALUs RX 7900 XTX has either 6,144 (how we prefer to understand it) or 12,288, as each pair is capable of floating-point operations. It doesn’t matter, actually, as peak TFLOPS is the same no matter which side of the ALU fence you sit on.
61.44TFLOPS is exactly 10 billion times larger than the traditional ALU count. We arrive at this figure by multiplying the peak boost clock of 2,500MHz by the operations per clock, which in this case is four. Viewed on paper alone, RX 7900 XTX batters RX 6950 XT – the best of the last generation – into submission through massive firepower.
Making matters more confusing, AMD decouples the front-end clock from the shader clock. The reason to do so rests with saving power on the cores by running them more slowly, though with a boost clock of 2,500MHz, both shader and front-end clocks become synced again.
Radeon RX 7900 XTX In The Flesh
If you’re lucky enough to get your mitts on the Radeon RX 7900 XTX this side of Christmas – and we’re sure it’ll be on many wishlists – this is what greets you.

The retail box is heavily reminiscent of premium Radeon RX 6000 Series models and presentation is suitably luxurious. The mere act of lifting the lid causes the card to tilt upwards within the box. It’s a neat little feature that’ll have you opening and closing the box a few times, or it could simply be that I’m childish.
Thar she blows. The best consumer graphics card AMD has ever produced. In stark contrast to how Nvidia goes about building its hulking Founders Edition 40 Series cards, AMD’s is a picture of restraint.
Measuring 287mm long, 123mm high (top of heatsink to PCIe 4.0 x16 connector) and 50mm thick, it’s a 2.5-slot beastie looking suitably menacing when presented in mostly-black aesthetic. Standing a little higher than a regular I/O bracket, there’s enough room for a trio of 85mm fans to be evenly spaced across the card.

Additional height provides opportunity for two-zone lighting – above and below the central fan – and the glow is pleasant and muted. Sloping off the top is the angled Radeon branding.
Flipping the card over, AMD uses an all-encompassing rear heatsink that, unlike Nvidia RTX 40 Series cards, covers a full-width PCB. Build quality remains top-notch on this heavy-duty offering, which tips the scales at a considerable, but not outlandish, 1,808g. Perhaps AMD ought to have included a PCIe support bracket in the package.

For the first time, there’s an additional sensor whose job it is to the case temperature. The lower the temperature, made possible by great chassis cooling, the more possibility of the GPU clocking higher. Smart design.
AMD puts great store in the MBA cards adhering to restrained physical specifications which lend themselves to installation in a wide range of chassis. Continuing this theme, as is clearly obvious, the 355W Big Boss card uses two standard eight-pin connectors feeding a 20-phase VRM. No fancy, forward-looking ATX 3.0 12VHPWR cable to add to basket, for better or for worse.

We dig the three red heatsink fins located near the power section; they give the card a sporty look without going overboard on go-faster livery.
AMD’s ‘Radiance’ Display Engine feeds the four I/O ports. Offering two DisplayPort 2.1 – compatible monitors coming in early 2023, we’re informed – there’s also HDMI 2.1a and USB-C which also supports DisplayPort 2.1. AMD makes a big deal out of this feature as rival GeForce RTX 40 Series, for some strange reason, persist with DisplayPort 1.4a.

Radeon RX 7900 XTX ups its Navi 31 sibling by having 24GB of GDDR6 memory – 4GB per MCD – running at 20Gbps for that juicy 960GB/s of bandwidth feeding into Infinity Cache.
Performance

Our 5950X Test PCs
Club386 carefully chooses each component in a test bench to best suit the review at hand. When you view our benchmarks, you’re not just getting an opinion, but the results of rigorous testing carried out using hardware we trust.
Shop Club386 test platform components:
CPU: AMD Ryzen 9 5950X
Motherboard: Asus ROG X570 Crosshair VIII Formula
Cooler: Corsair Hydro Series H150i Pro RGB
Memory: 32GB G.Skill Trident Z Neo DDR4
Storage: 2TB Corsair MP600 SSD
PSU: be quiet! Straight Power 11 Platinum 1300W
Chassis: Fractal Design Define 7 Clear TG
Our trusty test platforms have been working overtime these past few months, and though the PCIe slot is starting to look worse for wear, the AM4 rigs haven’t skipped a beat.
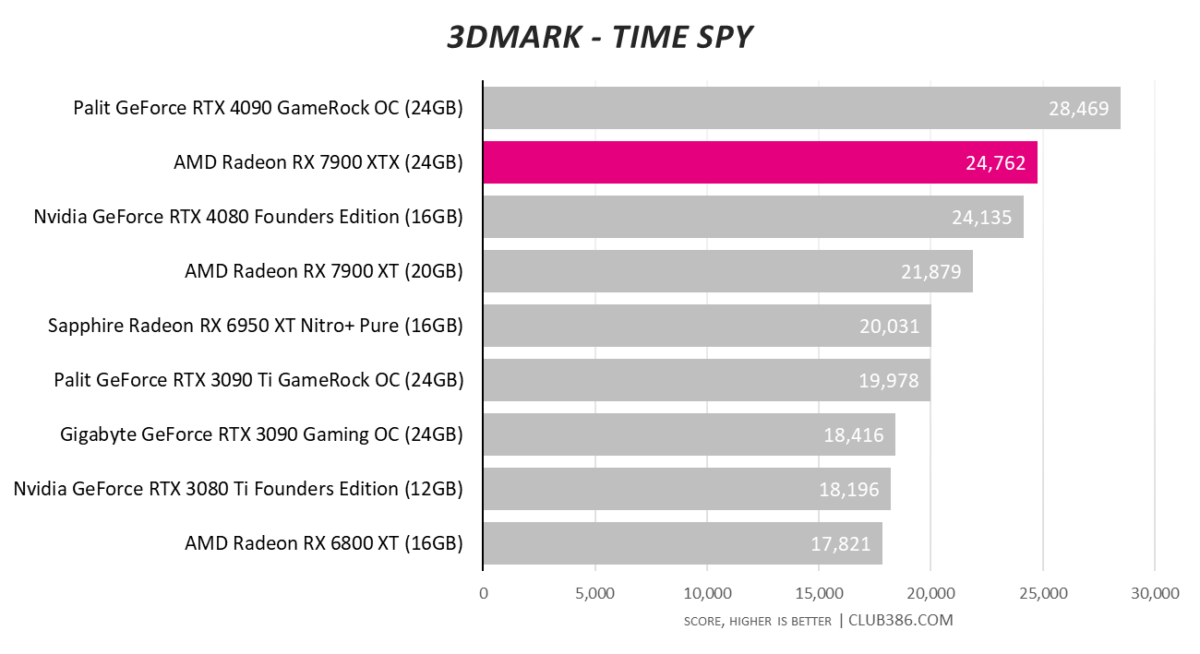
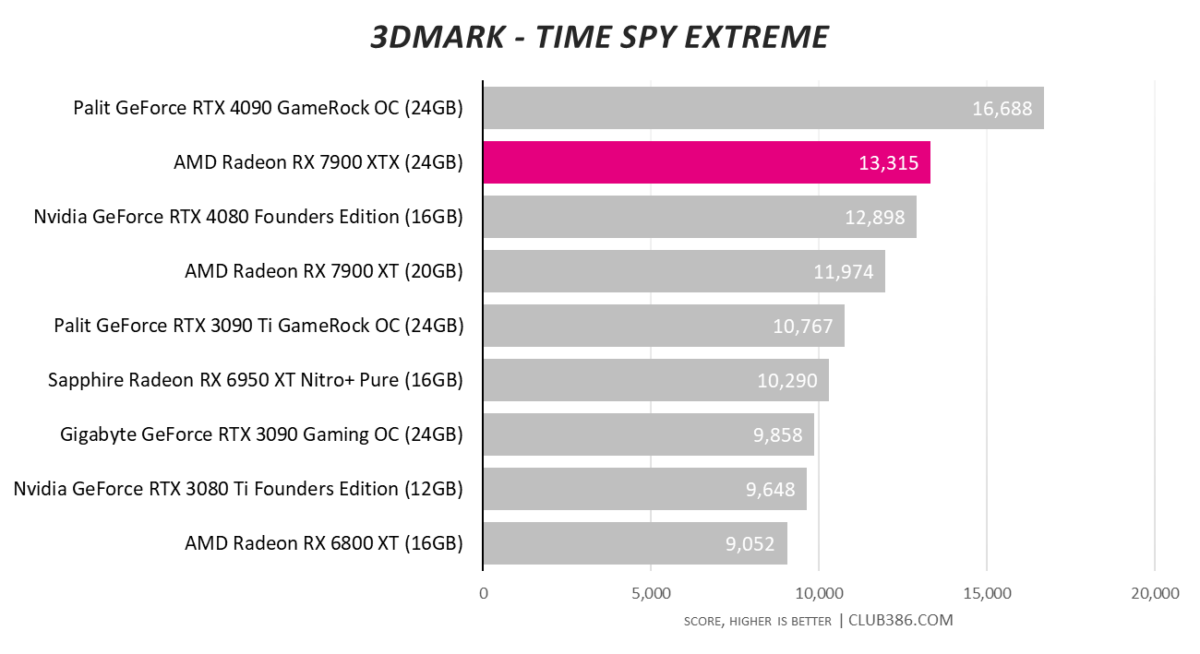
It is only fair to consider every card at its recommended retail pricing. Radeon RX 7900 XT is no match for the GeForce RTX 4090… but that’s okay. They don’t play in the same playground.
Coming in at $1,199, or $200 dearer than XTX, Nvidia’s RTX 4080 is marginally slower in the first two tests. A good start.
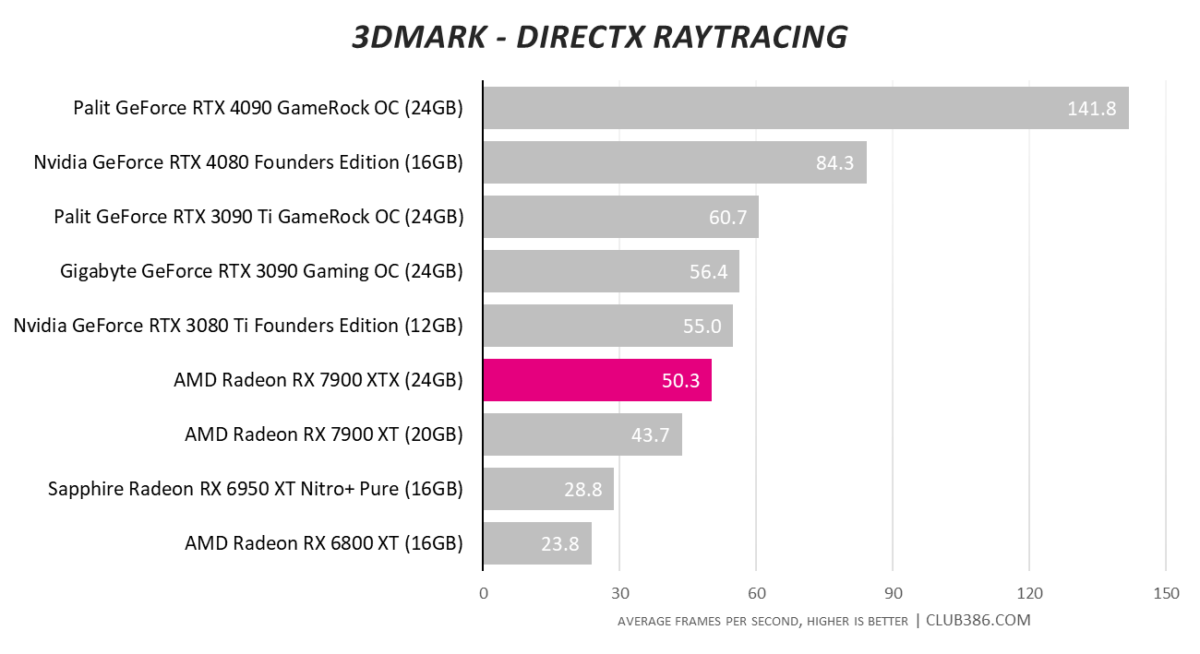
AMD has made claims of boosting ray tracing performance by 80 per cent compared to the previous generation. We spy a 75 per cent pure RT gain when compared to an admittedly overclocked RX 6950 XT, so kudos to AMD for not overegging the pudding.
The problem faced by RDNA 3 is that best-ever Radeon numbers still aren’t as good as Nvidia’s RTX 30 Series champions, let alone anywhere near RTX 40 Series.
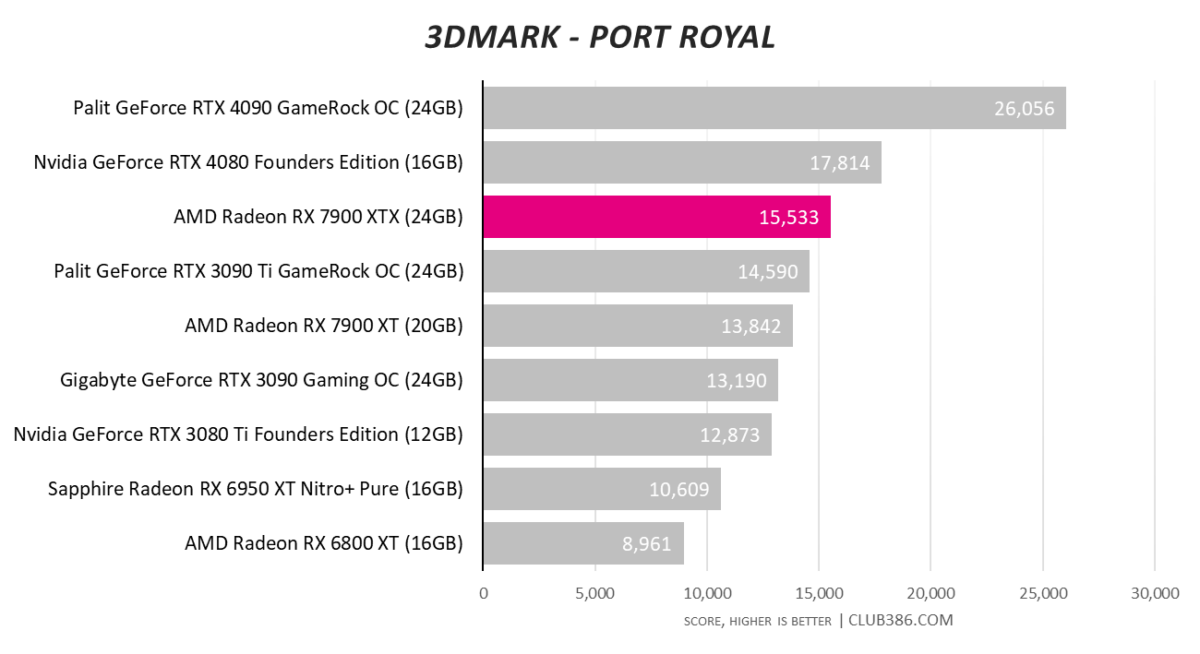
Combining rasterisation and ray tracing, RX 7900 XT puts up a good showing. As it should when one considers the core is humming along at a real-world 2,600MHz.
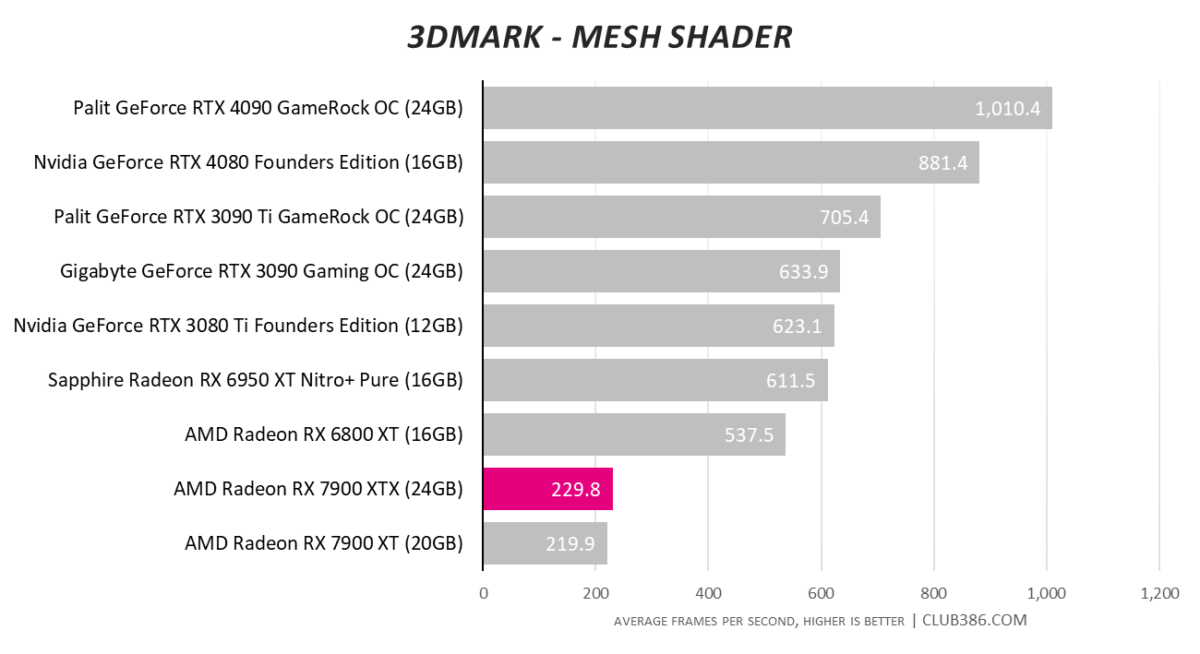
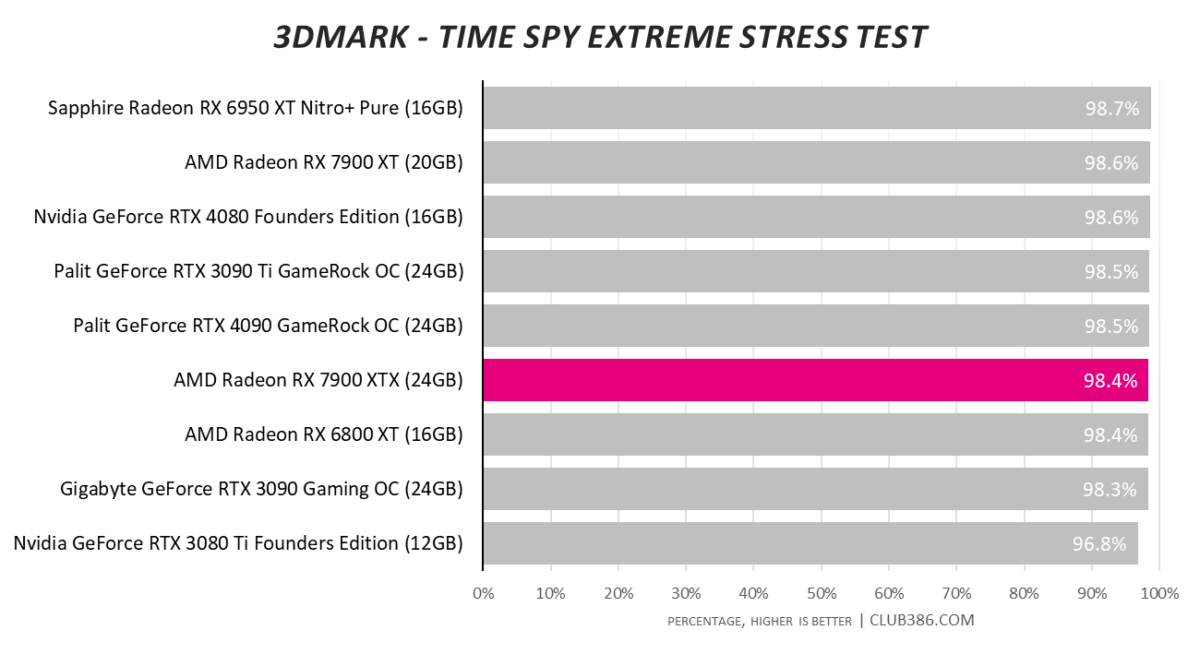
Something’s not right in this test. We’re investigating the matter.
Assassin’s Creed Valhalla
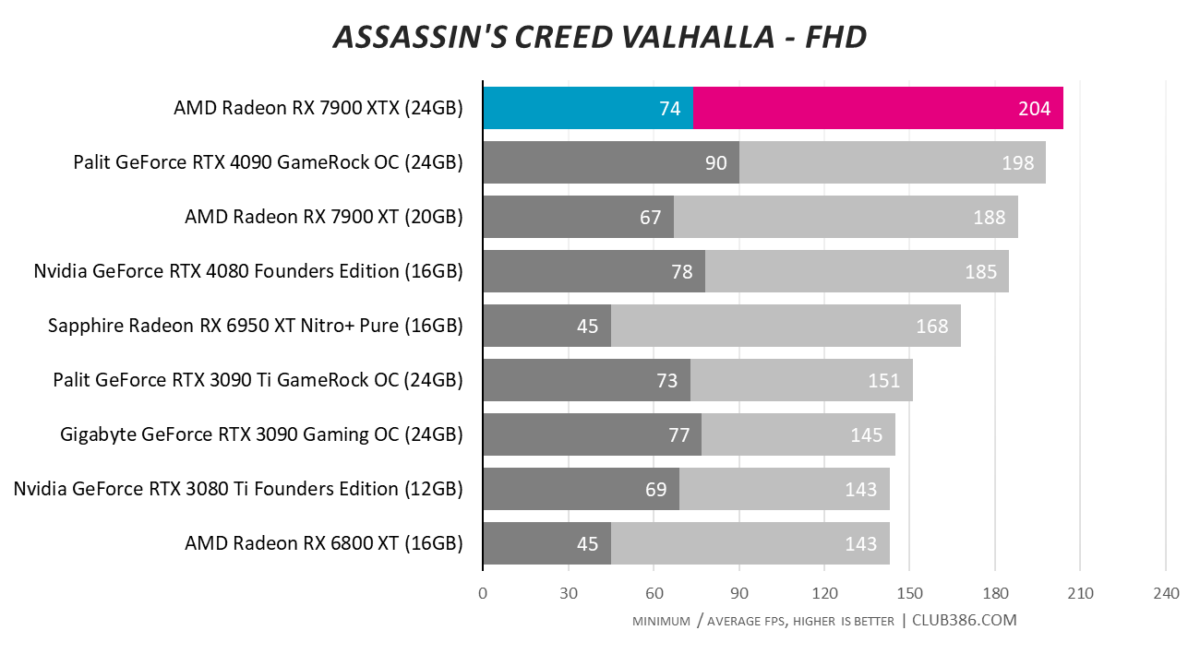
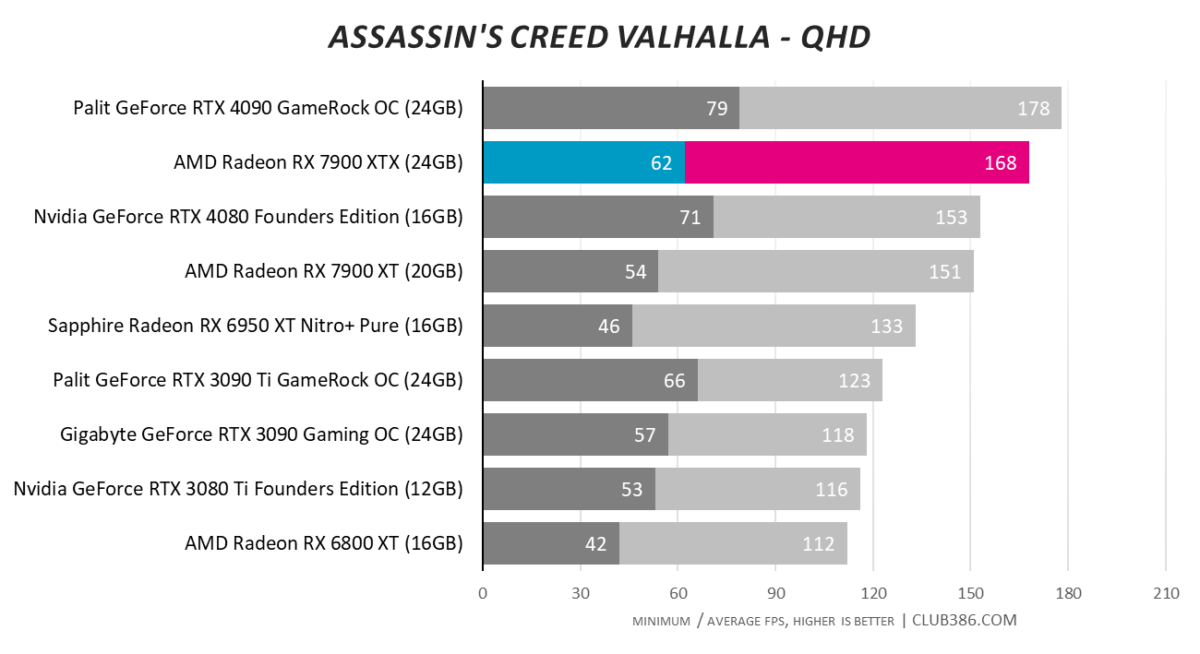
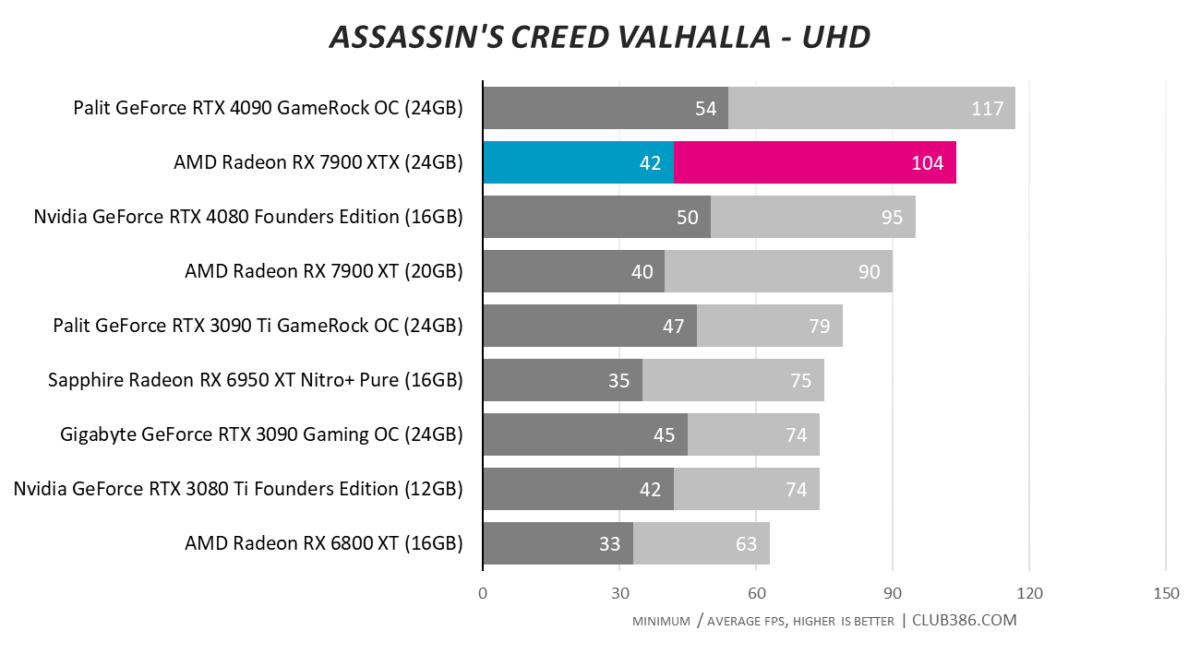
Graphing three resolutions in Valhalla is for educational purposes. UHD is where this card earns its keep. Sandwiching the two RTX 40 Series cards and almost 40 per cent quicker than RX 6950 XT, the $999 RX 7900 XT does very well.
Cyberpunk 2077
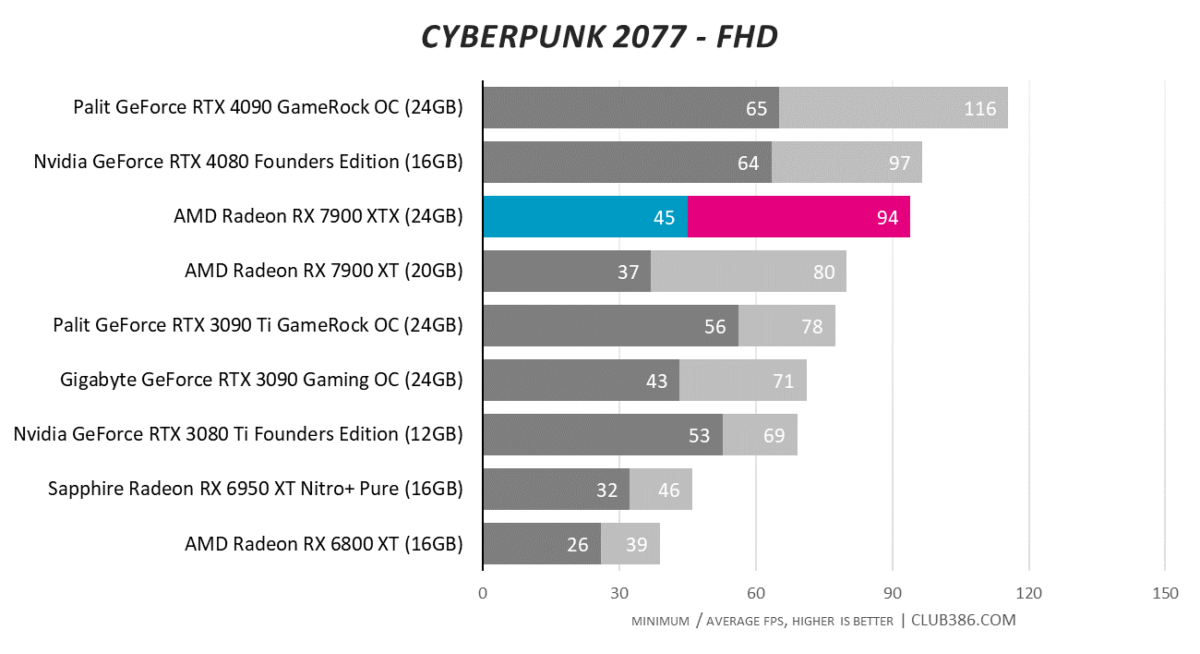
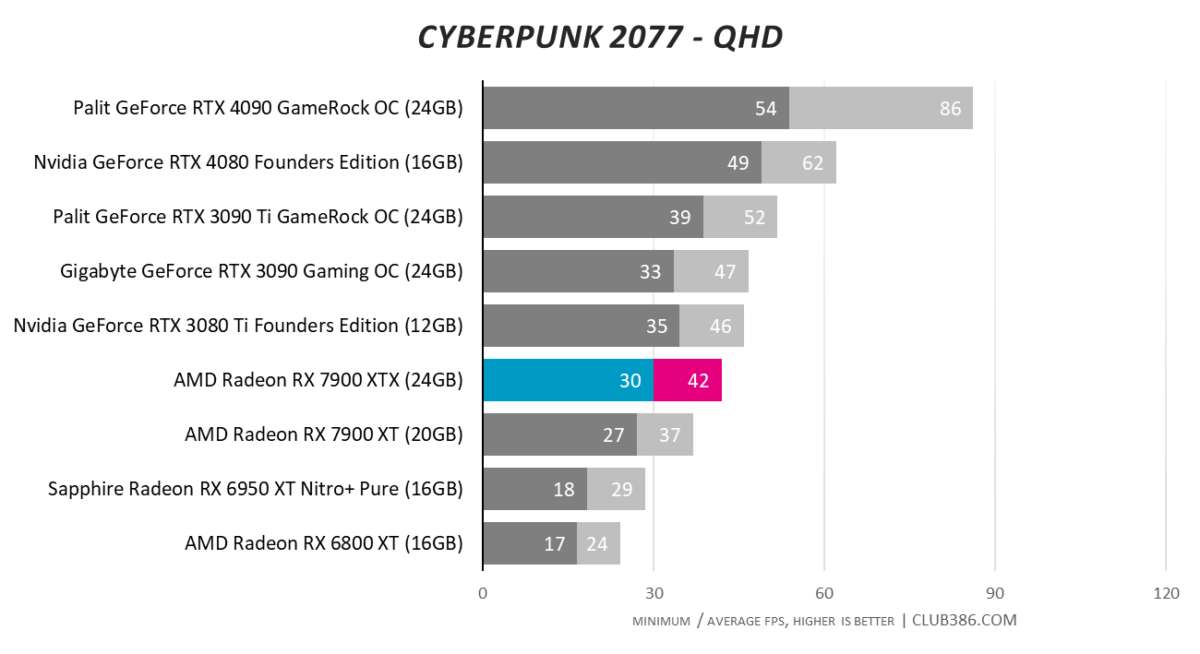
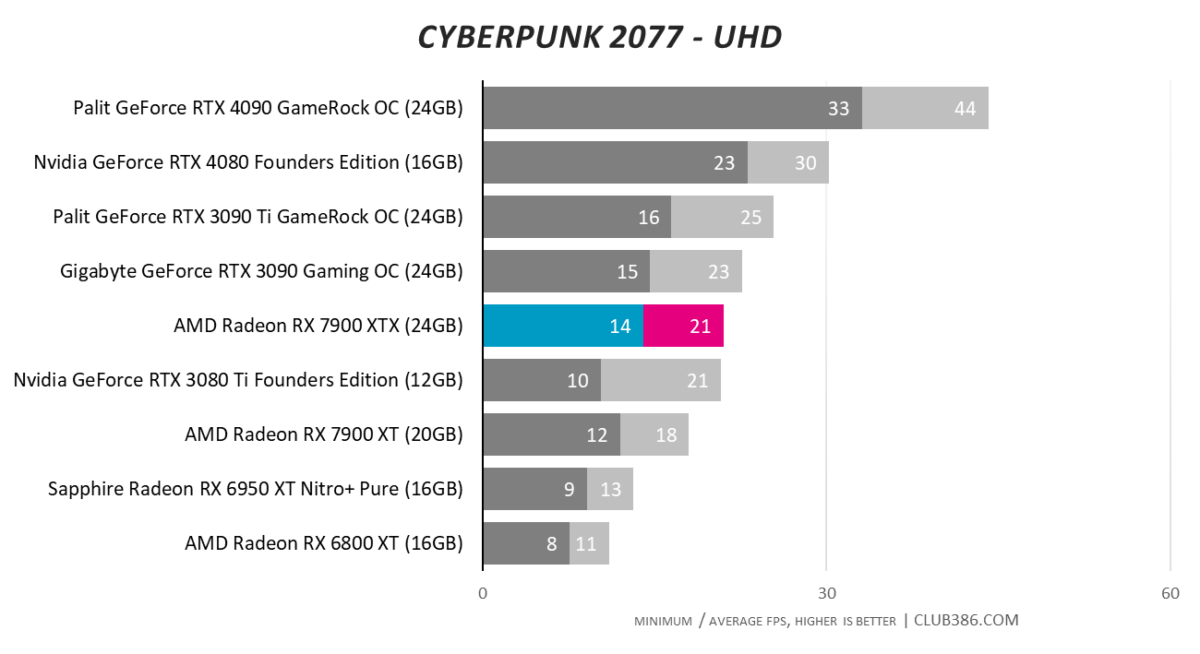
Running Cyberpunk at RT Ultra settings really separates the ray tracing wheat from the chaff. Starting off decent at FHD where there is minimal RT load, matters take a turn for the worse at QHD, where the best RDNA 3 card falls behind and RTX 3080 Ti. RTX 4080, meanwhile, is nearly 50 per cent as fast.
Turning the screw by evaluating at UHD shows AMD has made good strides in RT, but good is relative.
Far Cry 6

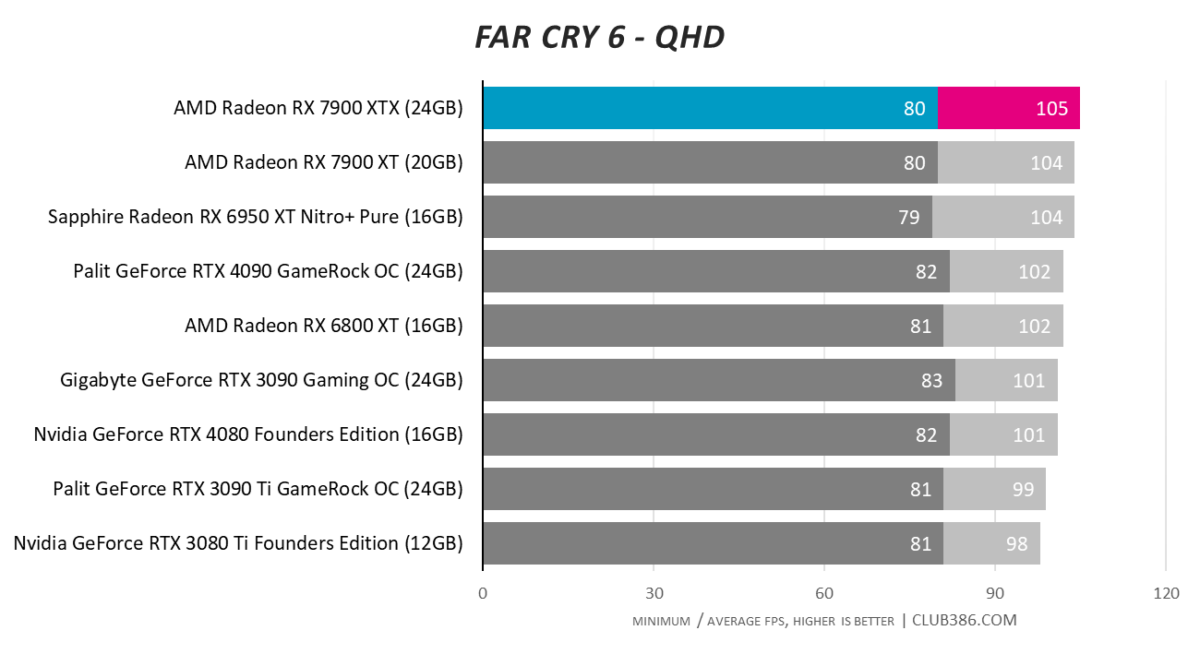
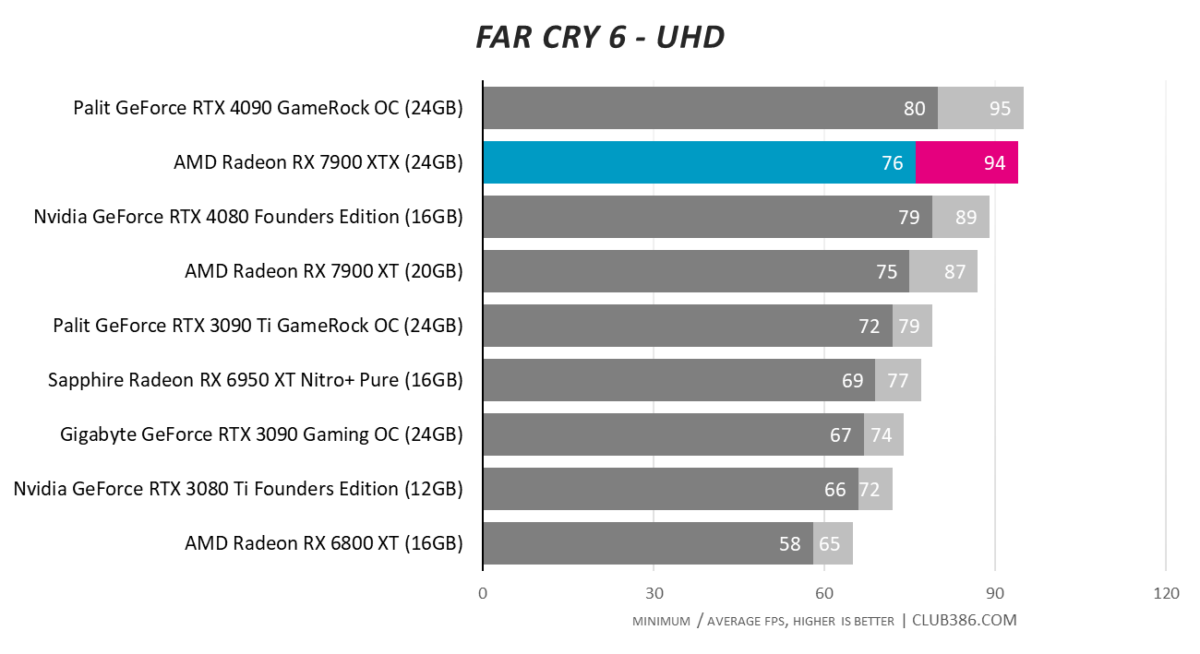
Nothing to complain about here; we also use DXR to further heighten the load. RX 7900 XTX passes with flying colours.
Final Fantasy XIV: Endwalker
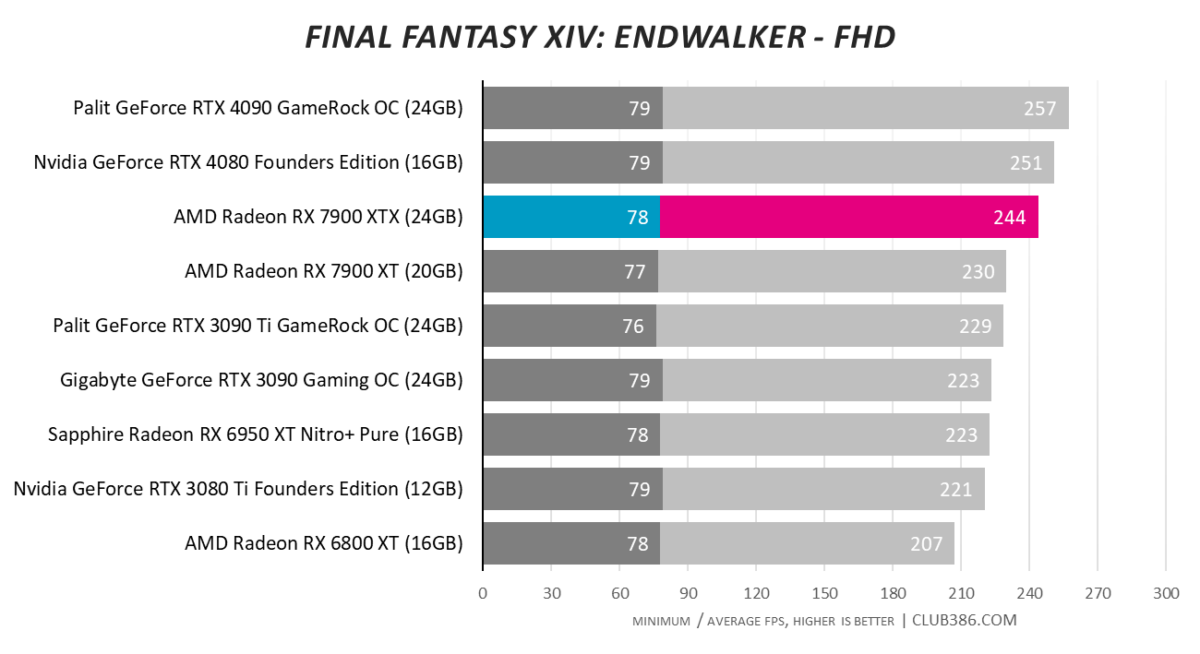
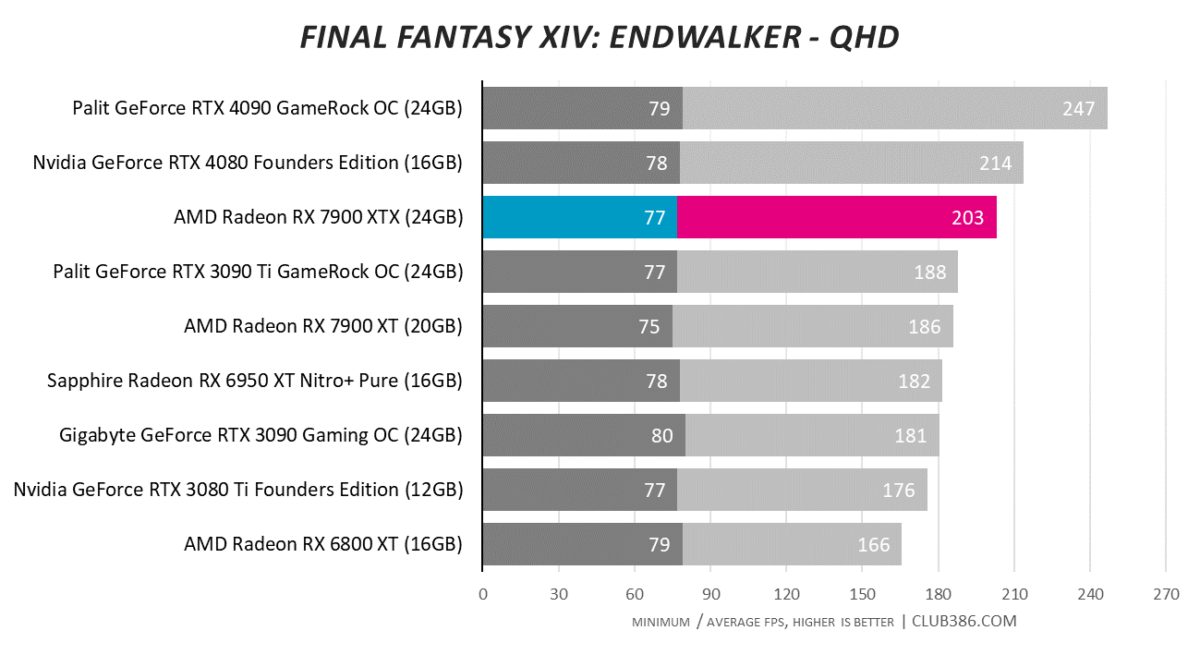

Rasterisation? Check. Performance above its pay grade? Check.
Forza Horizon 5
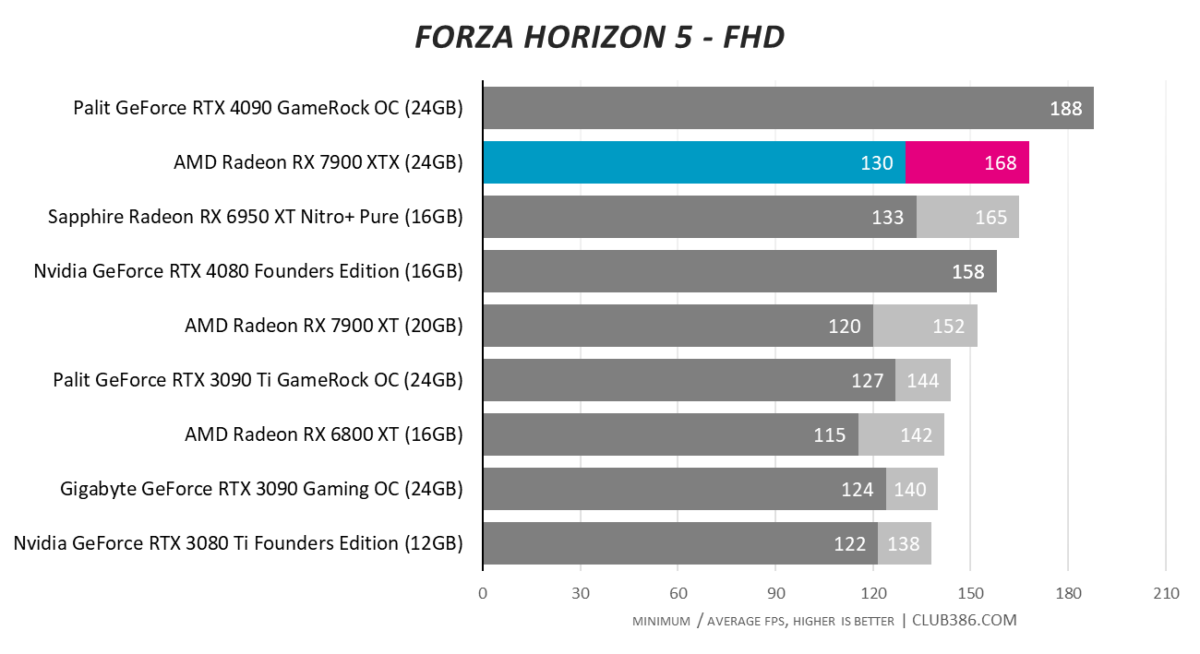
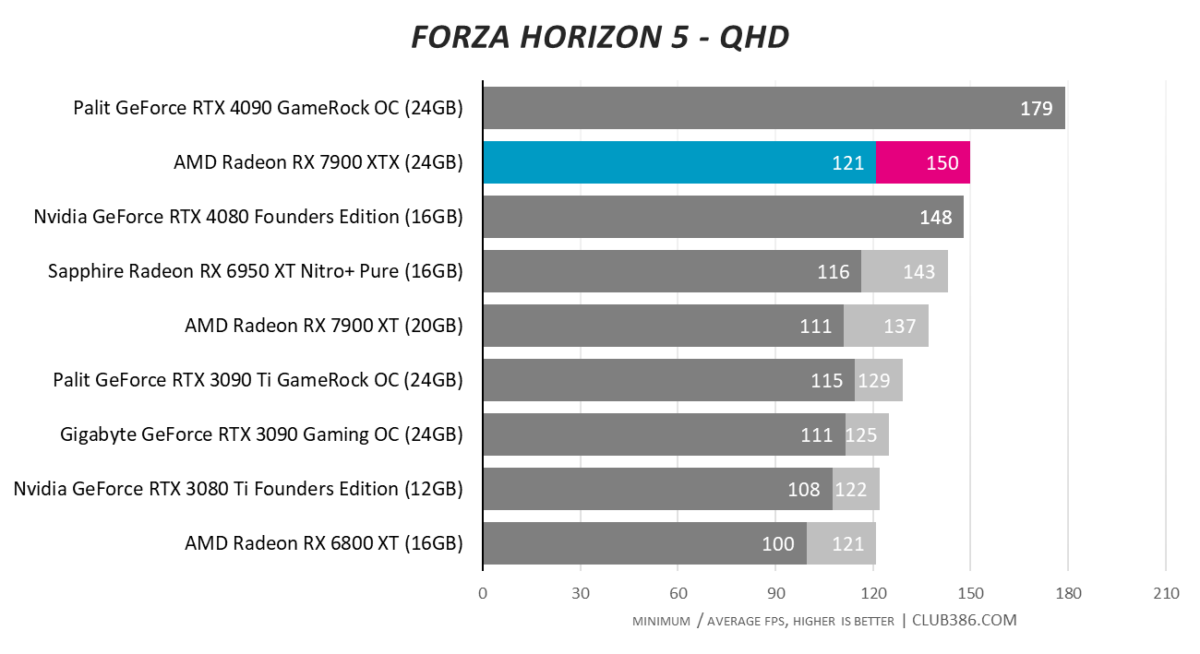
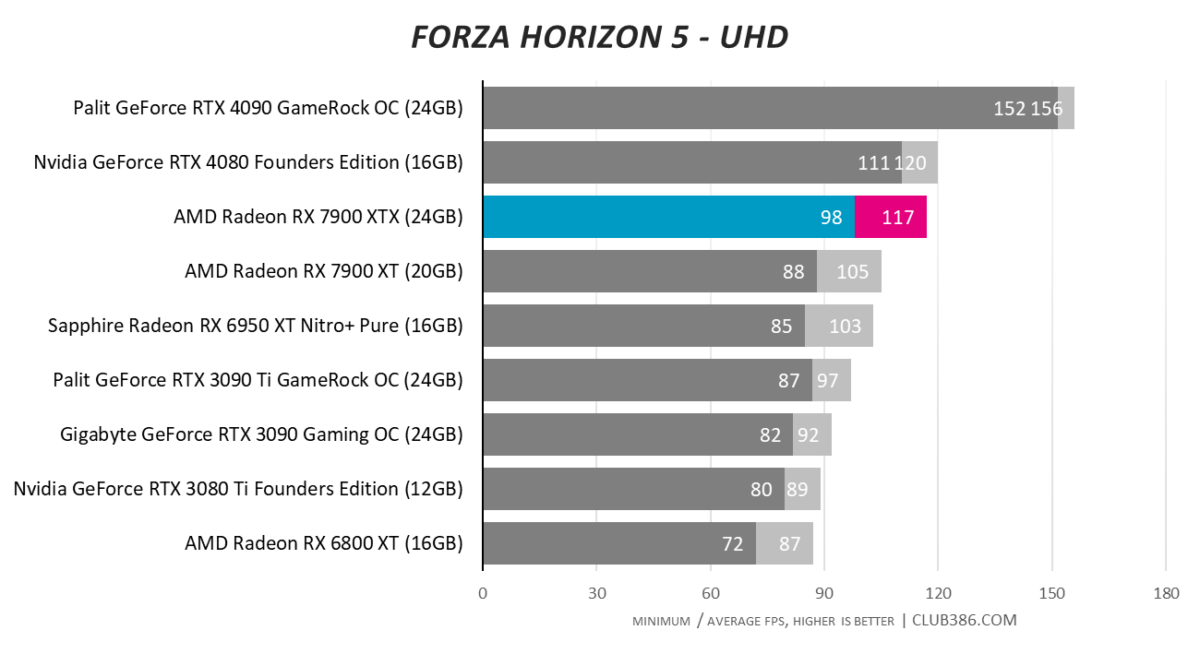
AMD has priced RX 7900 XTX bang on the money going by performance thus far. Close to RTX 4080 but $200 cheaper means it’s a good shout.
Marvel’s Guardians of the Galaxy
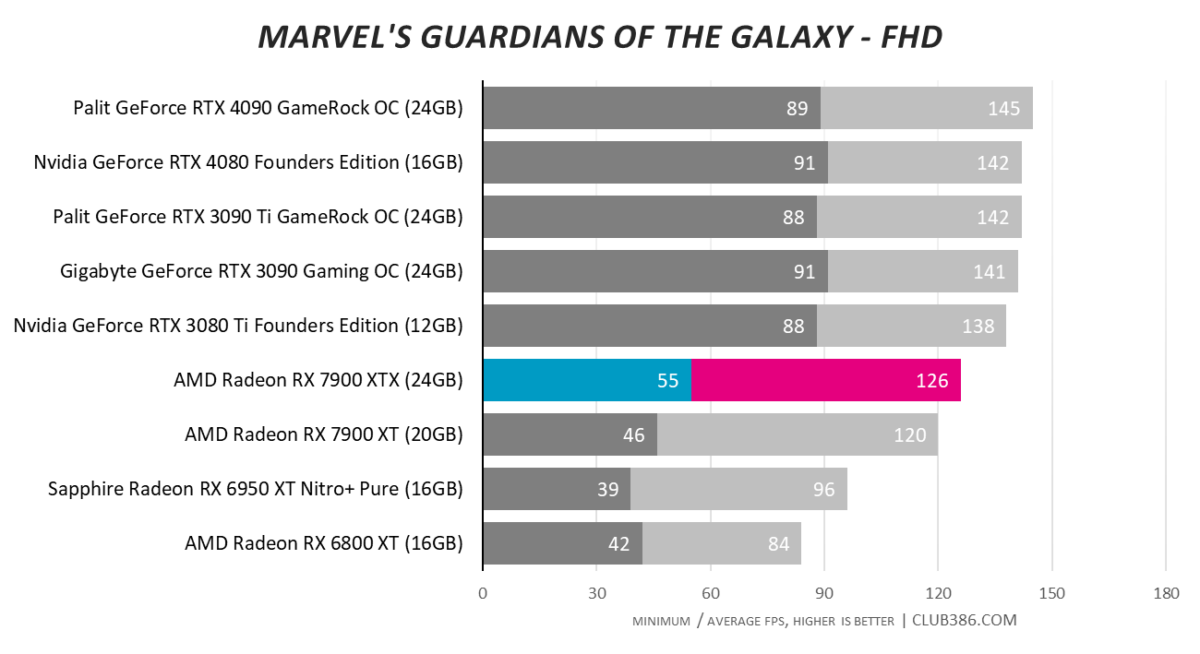
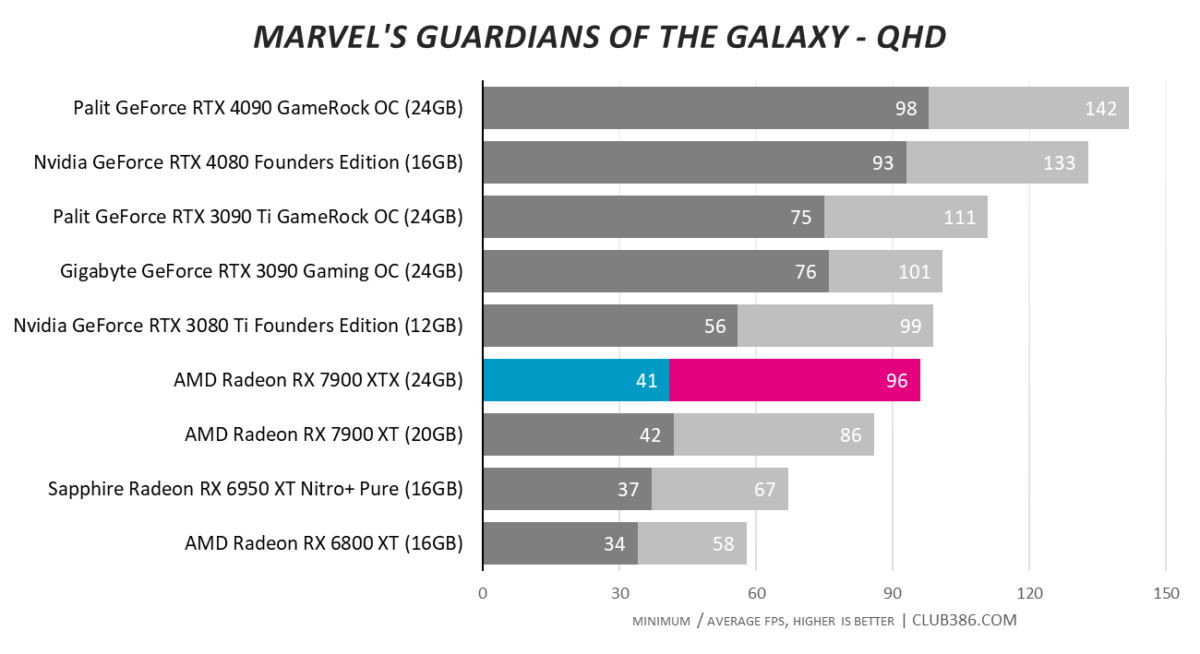
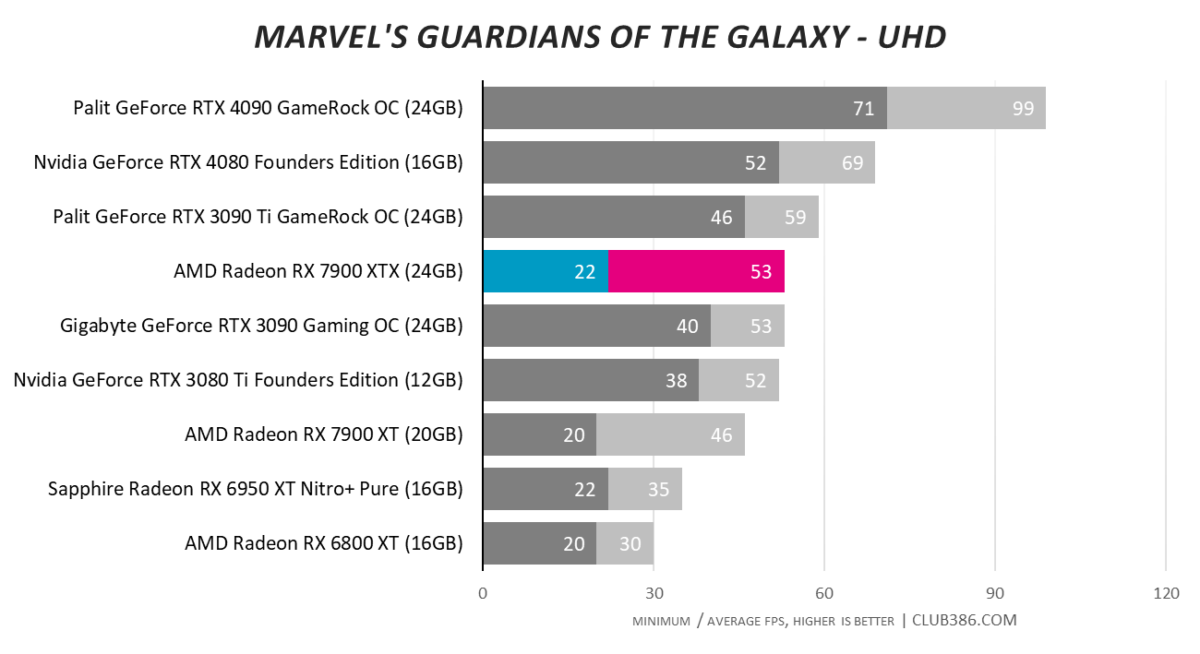
The RT spectre comes back to haunt RDNA 3. There are two ways to look at this; one is that RT-laden numbers are at least 50 per cent better than an RX 6950 XT. The second is AMD continues to play second fiddle to Nvidia.
Tom Clancy’s Rainbow Six Extraction
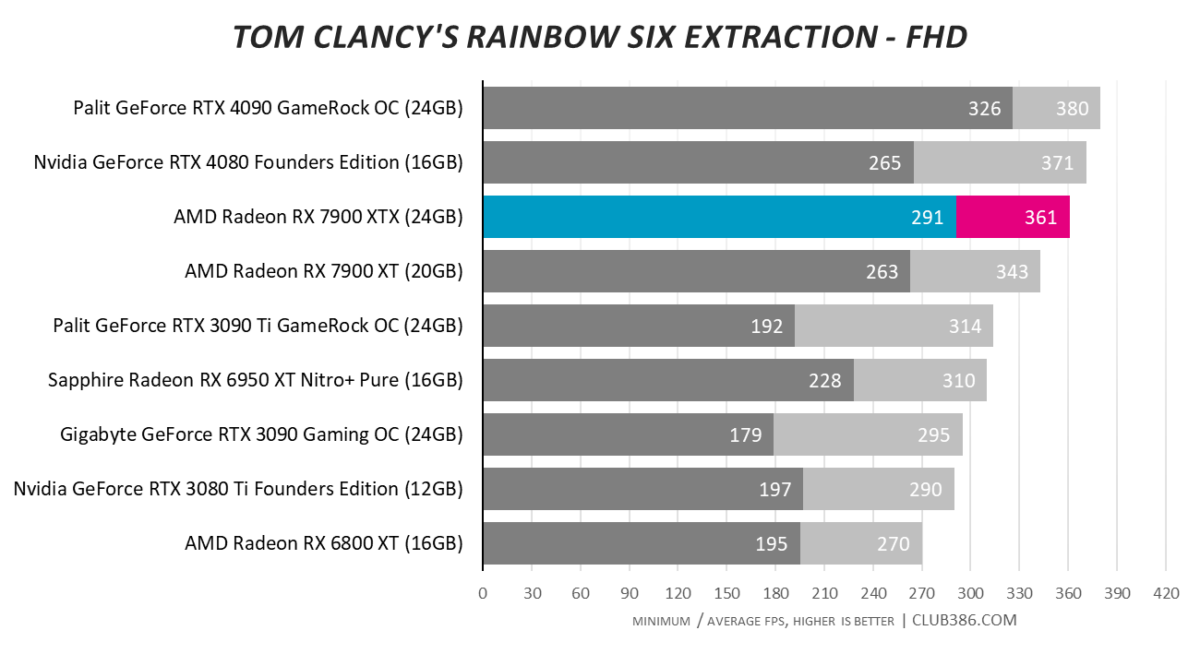
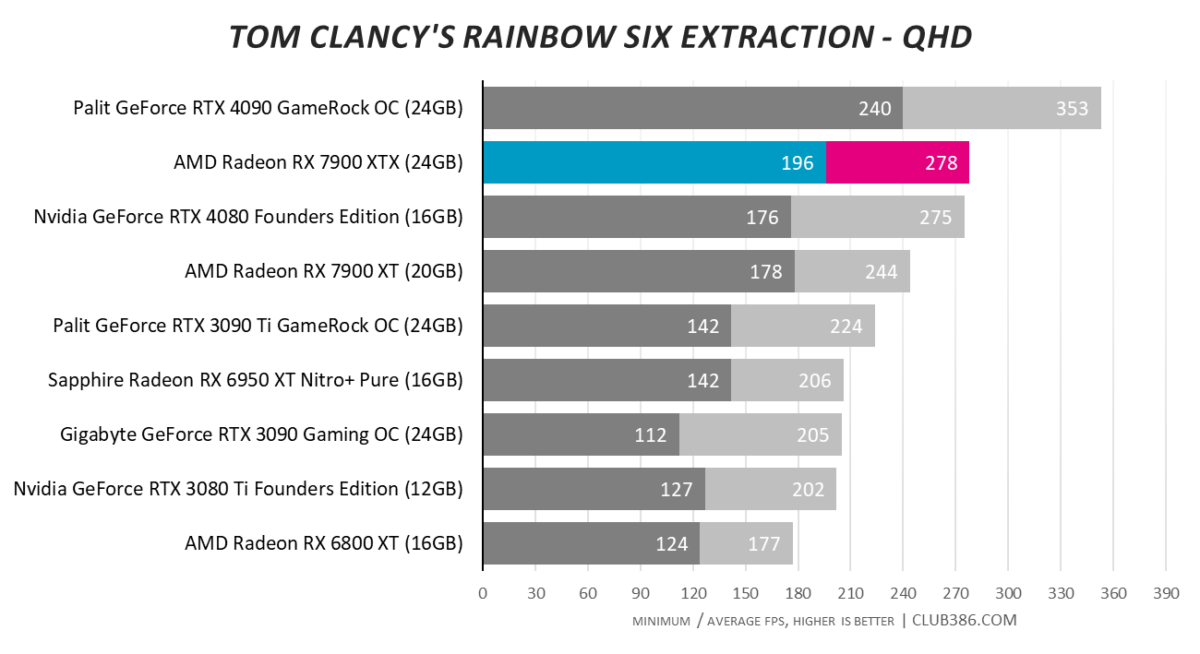
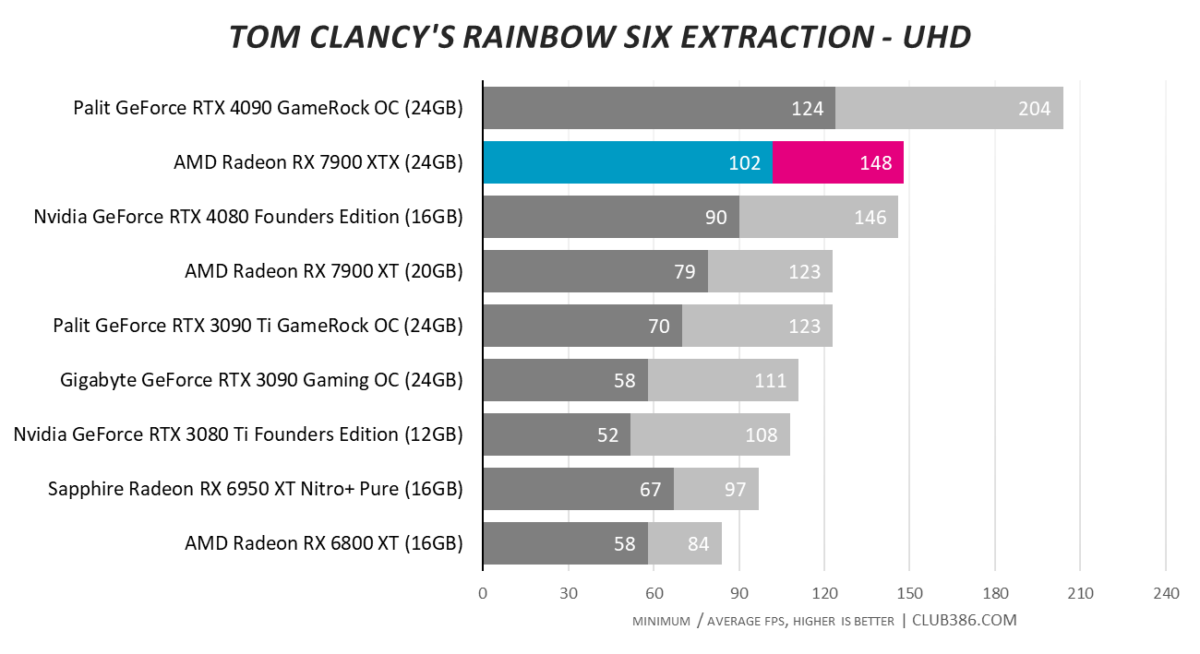
Tasty. RX 7900 XTX squeaks past RTX 4080.
Power, Temps and Noise
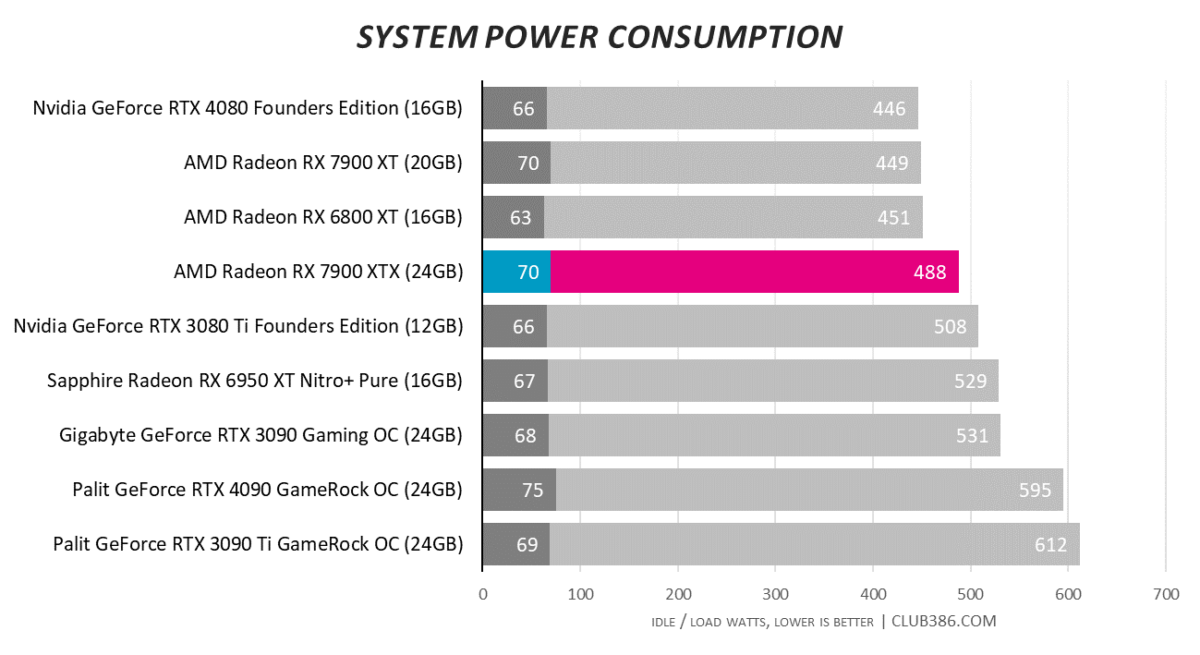
Outfitted with a 355W TDP, system-wide power consumption is more than acceptable for a premium graphics card. AMD’s chiplet approach is potentially beset by many obstacles; great engineering has nullified any obvious pitfalls.
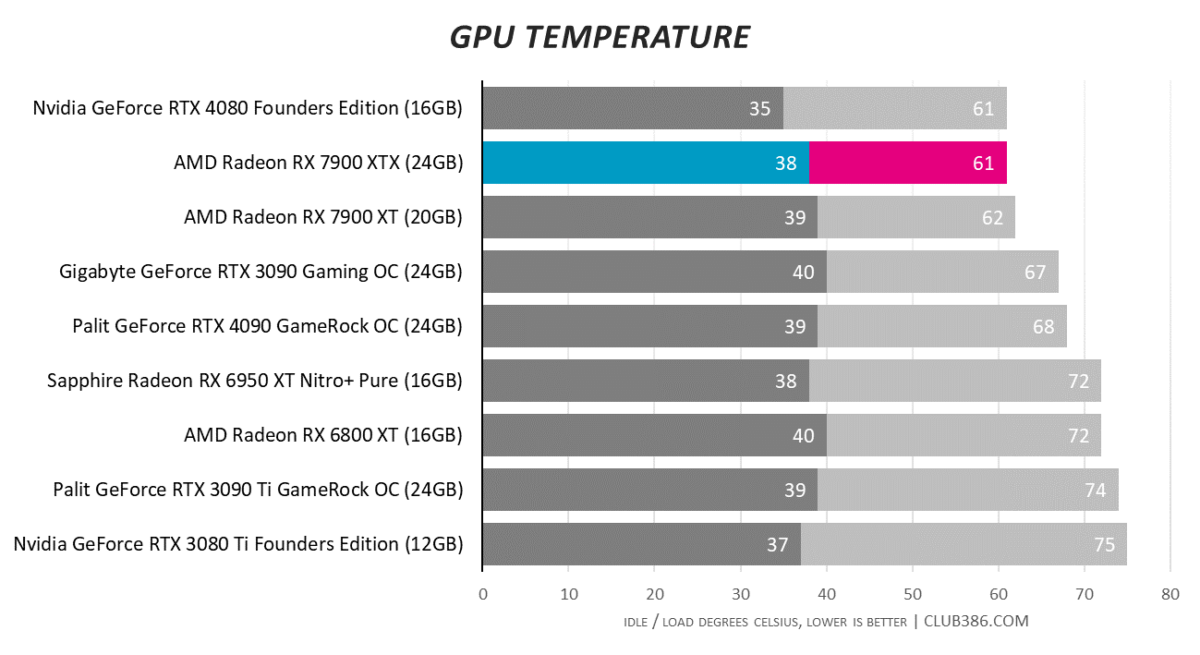
The fantastic cooler is barely tickled by full-on load. Temps are much improved for this generation.
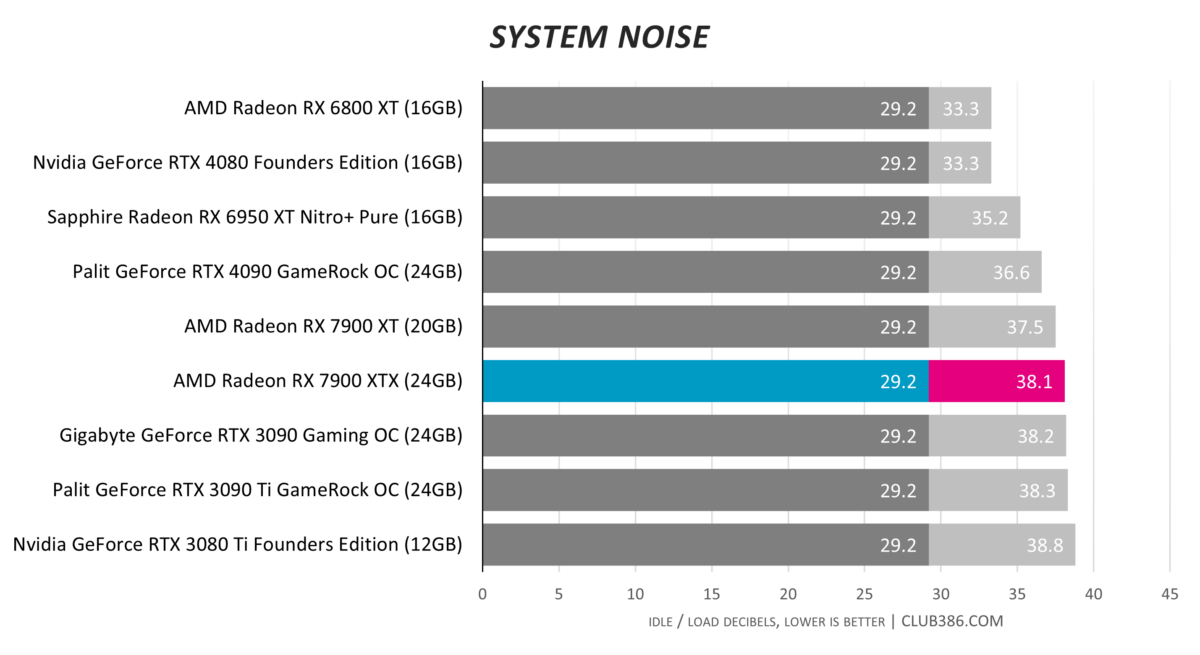
In fact, AMD could, and perhaps should, let the temperature scale to 70°C and operate with slower-spinning fans. The MBA card isn’t particularly distracting – the dB reading seems higher than our ears would lead us believe – but could be tweaked to run even quieter.
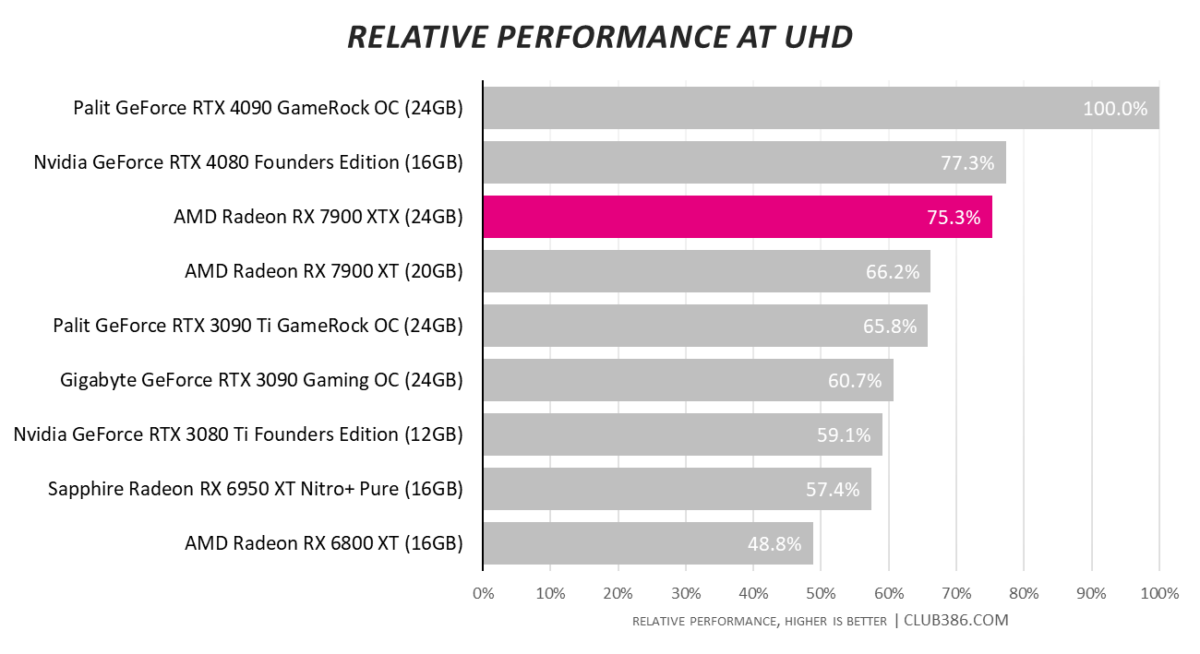
Evaluated over our selection of games, including three ray tracing titles, AMD’s premier consumer GPU comes in very slightly behind Nvidia’s RTX 4080. Being $200 cheaper can only mean one thing; good relative value.
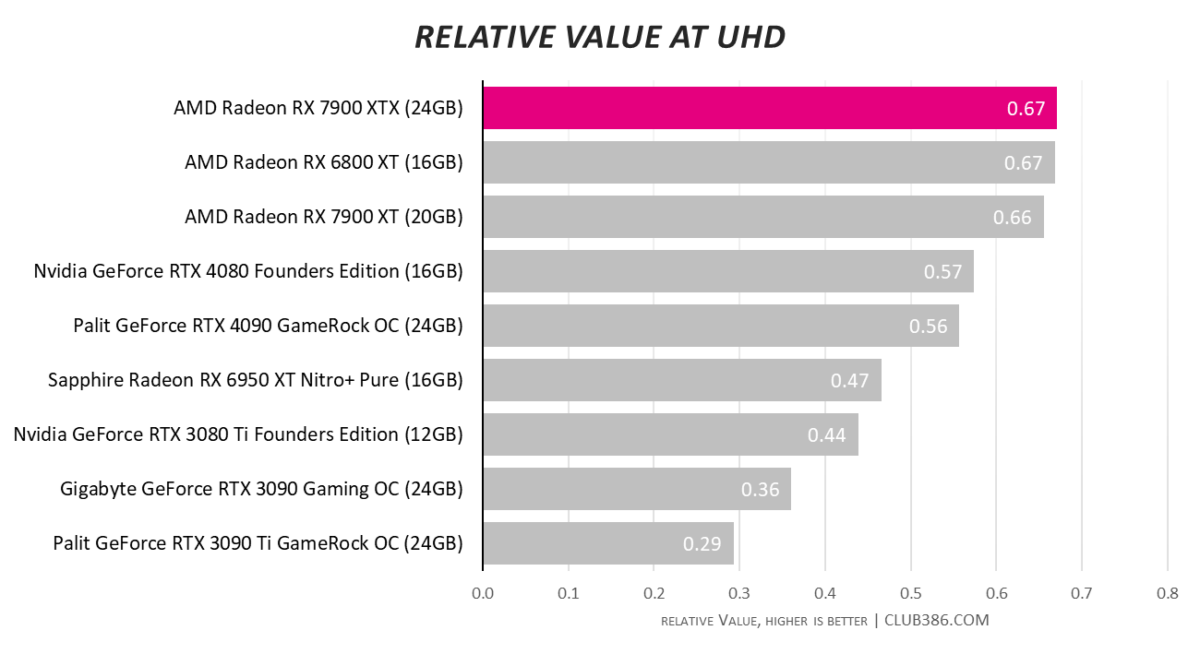
AMD’s aggressive pricing is very much on show as it gobbles up the top three spots. Can’t argue with the cost of the card when it routinely delivers 4K60 performance.
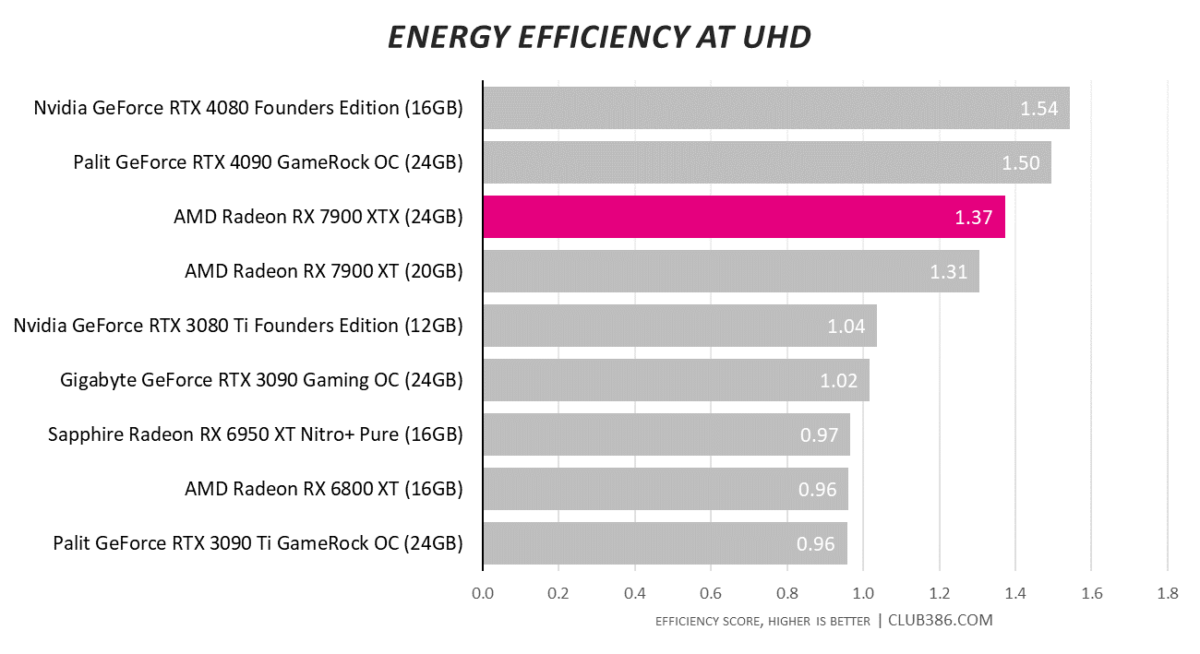
We wonder if a monolithic RX 7900 XT – not that such a chip will ever see the light of day – would top this chart? AMD still does well considering it’s chosen to devote a decent chunk of die space and power to connecting six MCDs to a central GCD.
Conclusion
Fully appreciating ever-increasing silicon cost for cutting-edge fabrication processes, especially for large, monolithic dies typically home to premium GPUs, AMD took on the considerable engineering challenge of building chiplet-based graphics cards for this generation powered by RDNA 3 smarts.
There’s short-term pain going down this approach because connecting seven chiplets together requires new technology which takes up additional die space and power. Nevertheless, AMD has succeeded in tying half-a-dozen MCDs to a central GCD. Bravo to the engineering team. It’s a bold strategy that ought to pay off in future designs that are inherently more complex.
Yet Navi 31 is more than a novel approach to design. AMD’s RDNA 3 architecture goes big on floating-point prowess, cache sizes, bandwidth inside and to the GPU, frequency, and improves ray tracing performance, whilst also bringing specific hardware for AI. Quite the shopping list.

The sum of these design choices lead us to today’s Radeon RX 7900 XTX 24GB graphics card. Opting for a chiplet approach takes some performance off the table – a necessary evil, if you will – but we come away pleasantly impressed with how well top dog RDNA 3 competes.
Fascinatingly, AMD and Nvidia approach high-end graphics with divergent philosophies. The Radeon crew is intent on building infrastructure that makes future fabrication simpler and less expensive. GeForce, meanwhile, uses specific framework to increase visual fidelity right here, right now. Tensor Cores, frame generation and class-leading RT come to mind. The perfect GPU, one imagines, is a combination of both approaches.
Let’s be clear. The Nvidia GeForce RTX 4090 stands alone and is the undisputed performance king for consumer graphics. As it should be given its $1,599 pricing. $999 Radeon RX 7900 XTX, meanwhile, is more than a match for second-rung, $1,199 RTX 4080 in common rasterisation games. AMD also provides solid generational uplifts in ray tracing throughput – up to 80 per cent over RDNA 2 – yet that’s only enough muscle to match Nvidia’s last-gen cards. And speaking about the elephant in the room, there’s no immediate answer to Nvidia’s excellent frame-generation technology that’s a cornerstone of RTX 40 Series’ appeal.
We talk about relative value when referencing $1,000 GPUs outside the financial scope of many gamers. Part of us wanted AMD to release budget RDNA 3-infused cards first, addressing the ~$500 market, particularly in today’s economic climate, but here we are.
As the first onslaught of a chiplet-based RDNA 3 architecture in retail form, we believe AMD has a credible premium product with the £999.99 Radeon RX 7900 XTX. Understanding the extra physical complexity involved in the design, which ought to bear fruit in the future, that’s a great achievement in itself.
Verdict: AMD’s succeeded in creating the best $1,000 graphics card on the market. Over to you, GeForce RTX 4070 Ti.