
Taking a new approach to maximising server processor performance for select footprint-hungry applications, AMD announced L3 cache-enriched versions of Epyc 7003 Series in November 2021. Equipped with up to 768MB L3 per chip and known by the codename Milan-X, today we provide greater insight into how and why AMD chose to go down this path.
As a recap, regular third-generation Epyc server processors harness the Zen 3 architecture and house up to 64 cores and 128 threads. Each core carries 64KB of L1 cache and 512KB of L2, and nothing changes in this regard.
All of Milan-X’s goodness is focussed on enlarging the L3 footprint by a factor of three. Reason to do so, AMD says, is in enabling various technical computing workloads, which tend to have large in-flight memory requirements, to fit into on-chip cache, rather than be loaded from much slower main memory. Doing so improves performance hugely for certain applications requiring lots of cache, but being even-handed, this approach verges on pointless if the workload is compute bound rather than cache bound.
To be clear, Milan-X is designed to serve a relatively niche audience who implicitly understands workload bottleneck characteristics and identifies on-chip cache as a leading inhibitor.
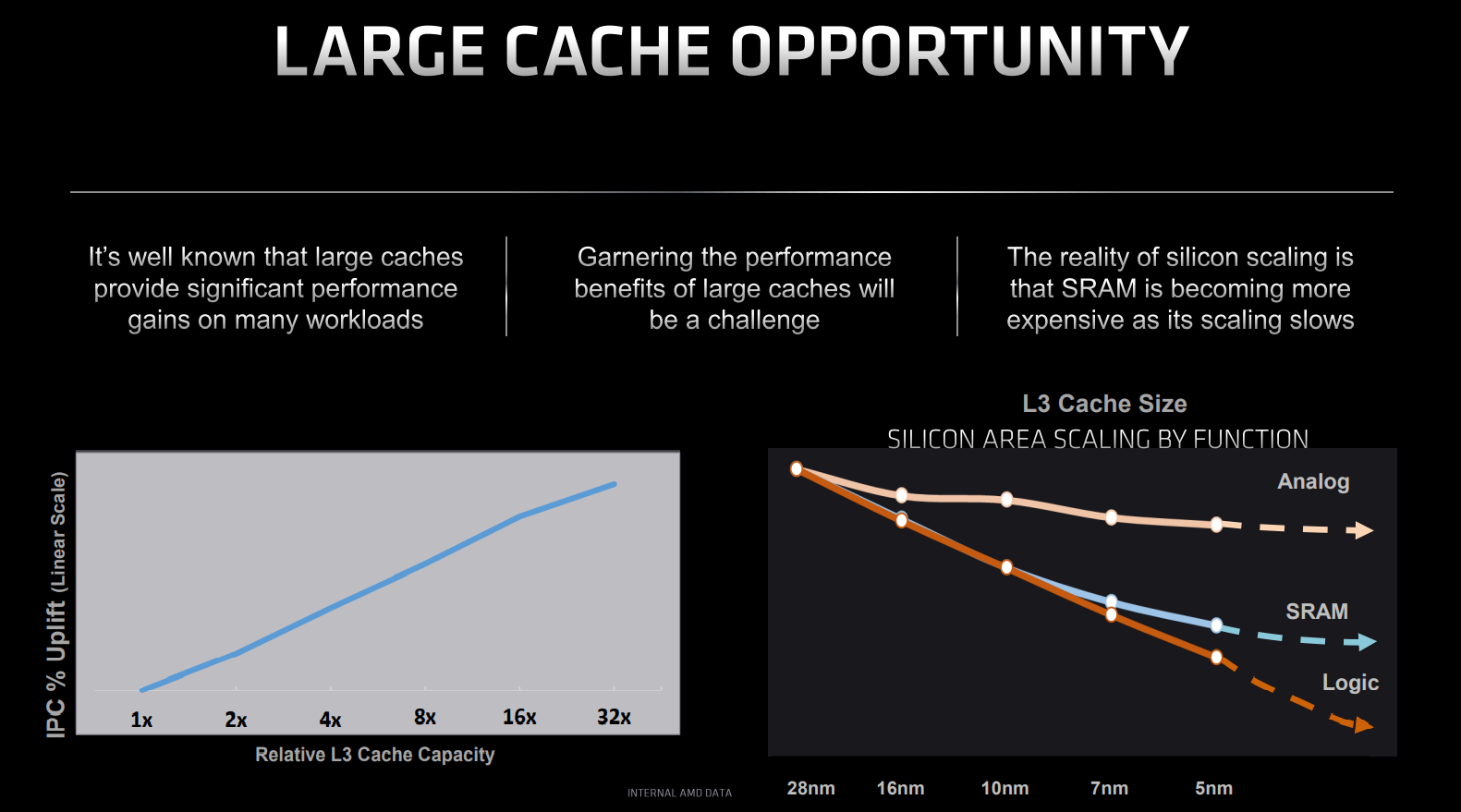
AMD offers great opportunity to leverage additional L3 on the same process node, if possible, because super-dense SRAM – the transistor building block for caches – does not scale well with iterative die shrinks. Going by the above AMD-supplied graphics, SRAM barely reduces in area when moving from 5nm to, say, 3nm.
This understanding explains why AMD chose to enhance current L3 cache in a novel way for specific workloads, and we’ll show interesting numbers further on down. The next question is how, because if adding L3 cache is a boon for IPC, why hasn’t this been done before?
Zen 3 built for cache stacking

The simplest reason for not adding heaps more L3 rests with enlarged die sizes and associated wiring complexity. Sure, AMD and Intel could previously double caches, but doing so would inflate per-chip silicon area to economically and thermally untenable levels. This is why we haven’t seen an Epyc or Xeon with 1GB L3 before.
What’s needed is a method of retaining the current silicon footprint and stacking extra L3 on top, in some fashion, without reducing bandwidth, whilst minimising additional access latency. A tall order. Enter Milan-X’s 3D V-Cache.
Shown above is a high-level single Core Complex Die (CCD) from Epyc Milan. Built on a 7nm process from partner TSMC the layout is instantly familiar. Eight cores each have access to 32MB of L3, and eight of these complexes are tied together to form the 64C128T headline chip. AMD says Zen 3’s CCD has deliberately been built with forward-looking 3D V-Cache in mind, and we know this because it features necessary copper through silicon via (TSV) hooks primed for adding dies on top.
Extra cache appears as one block
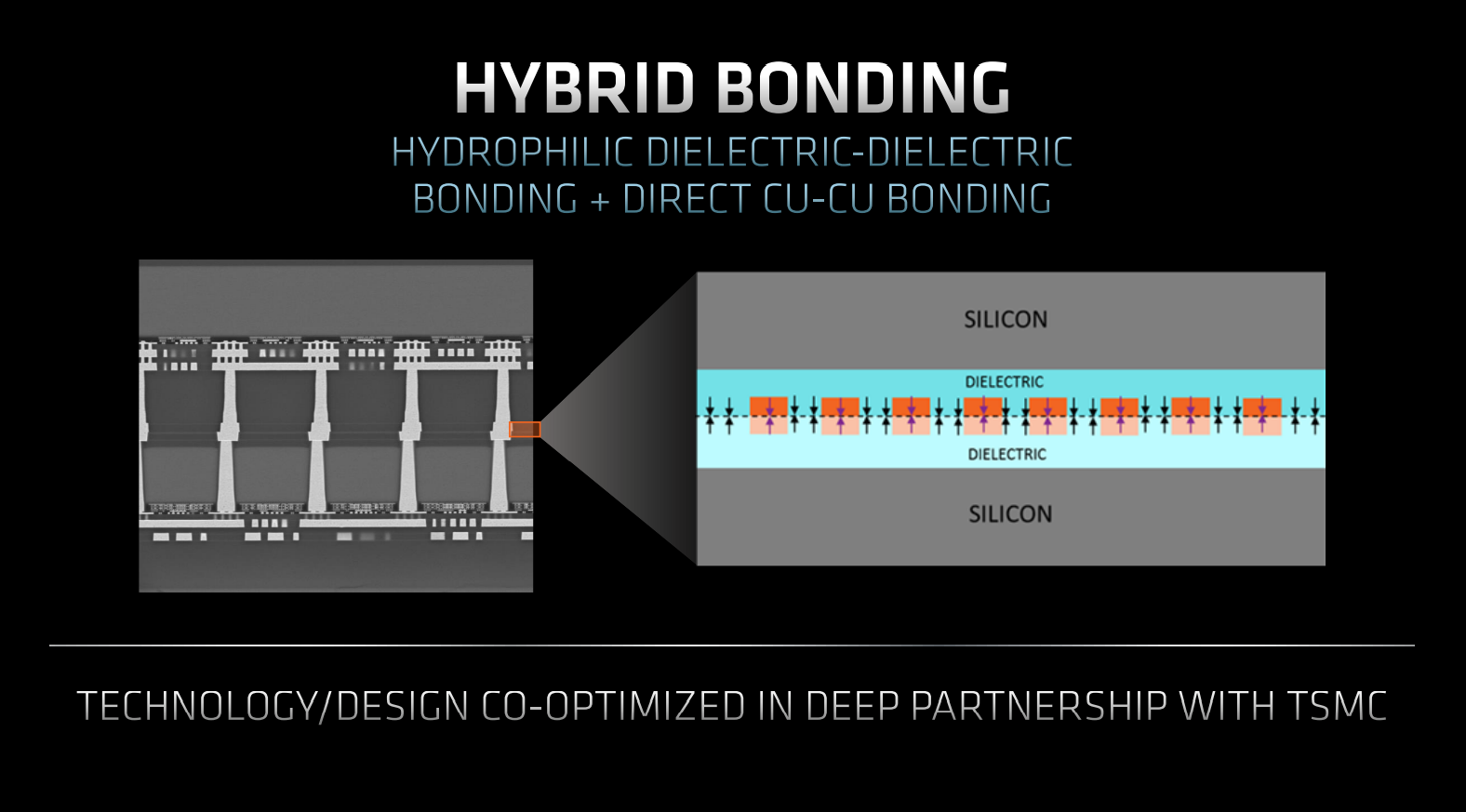
Co-designed with TSMC, AMD uses a technique known as hybrid bonding to deliver unfettered bandwidth from stacked L3. Cited as a ‘breakthrough capability’ by Sam Naffziger, AMD corporate fellow, a direct hydrophilic bond chemically fuses silicon dioxide on the existing L3 and stacked X3D. The hybrid name, constituting both chemical and metallurgical bonds, comes from joining copper to copper, as shown on the left.
Going down this approach enables ultra-dense layer-to-layer interconnects enabling stacked cache to behave like existing L3. This is possible as the base 32MB of L3 carries dense-enough wiring and ringbus controller to service any stacked cache. In other words, AMD thought about 3D V-Cache from day one; it cannot be retroactively ported over to other chips lacking TSV transmission support.
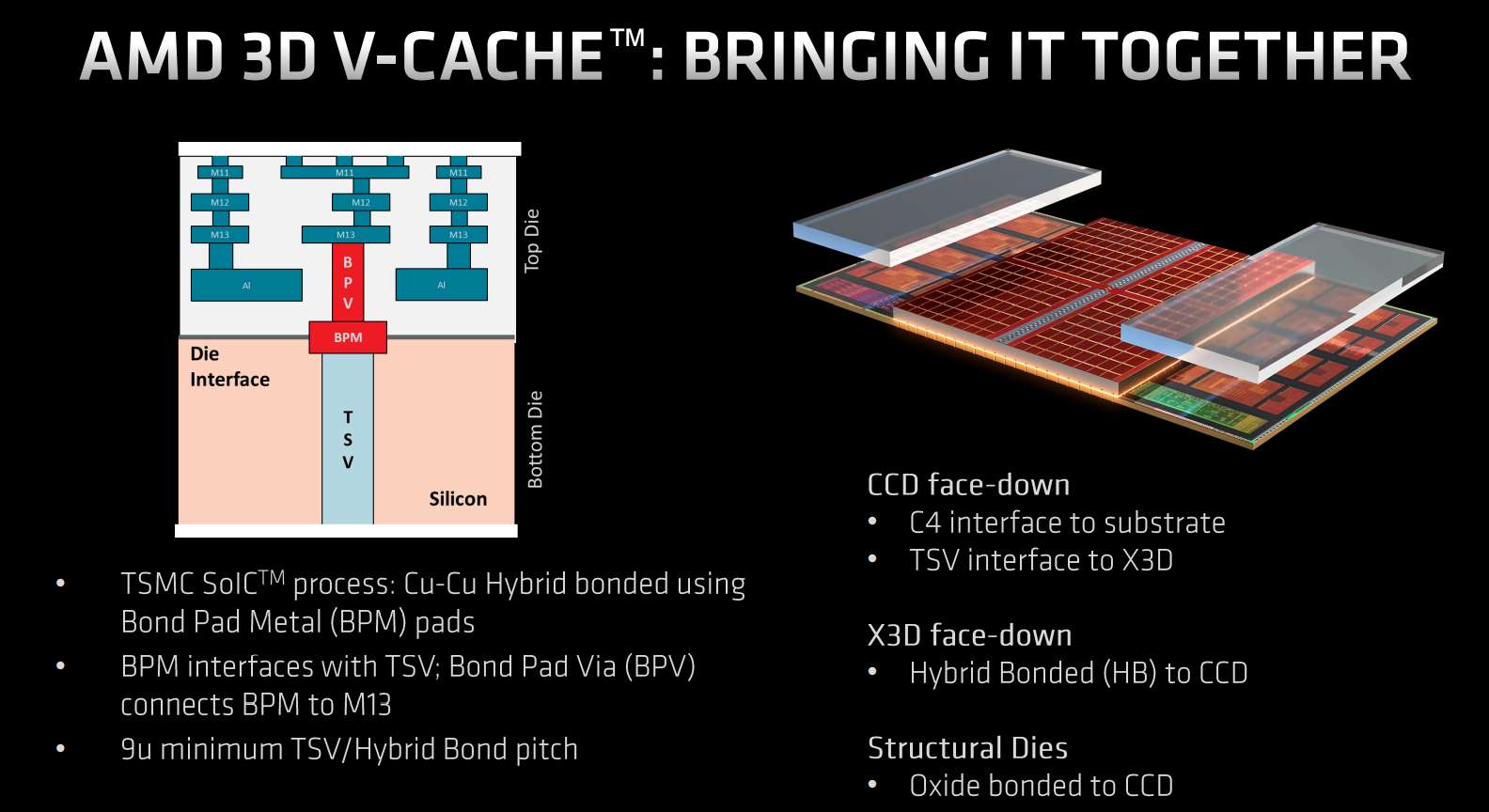
Two 32MB L3 stacks are laid on top of existing L3 by connecting through 9-micron TSV pitches at the 13th layer of the top die. Thinking it through, X3D is twice as dense as extant base L3 for the same area – at the bottom, remember there is 16MB on each side – and it’s possible because X3D is all about dense, lower-power cache; there is no control logic or ringbus to think about.
The cores, and by extension operating system, are oblivious to the bonding of extra L3. Milan-X appears and largely performs like a triple-dense L3 monster. We say largely as there is a minor overhead of four cycles in accessing the upper cache, but that’s a pretty good return all things considered.
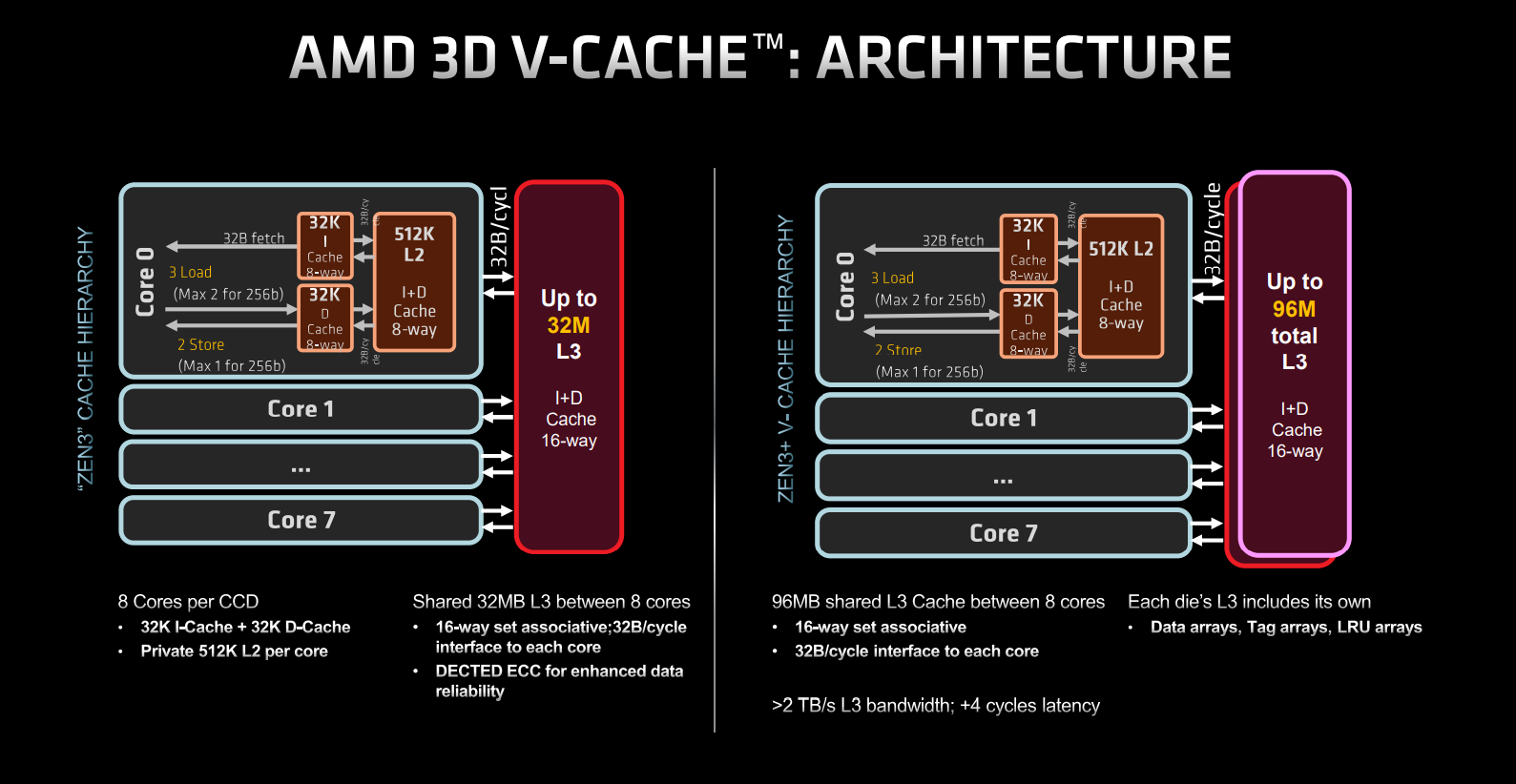
Another view of Milan (left) and Milan-X (right) CCD shows what’s going on. As explained earlier, everything is the same on the left-hand side; it’s only the L3 cache that’s different. Now, instead of 32MB per CCD we have 96MB appearing as one block, even though it’s actually two melded together.
Could AMD have used Milan-X to also increase L1 and L2 by a meaningful margin? Probably, but as customers tune their workloads to a base architecture and require application consistency, tinkering only with L3 is a safe bet.
AMD Epyc Milan-X models
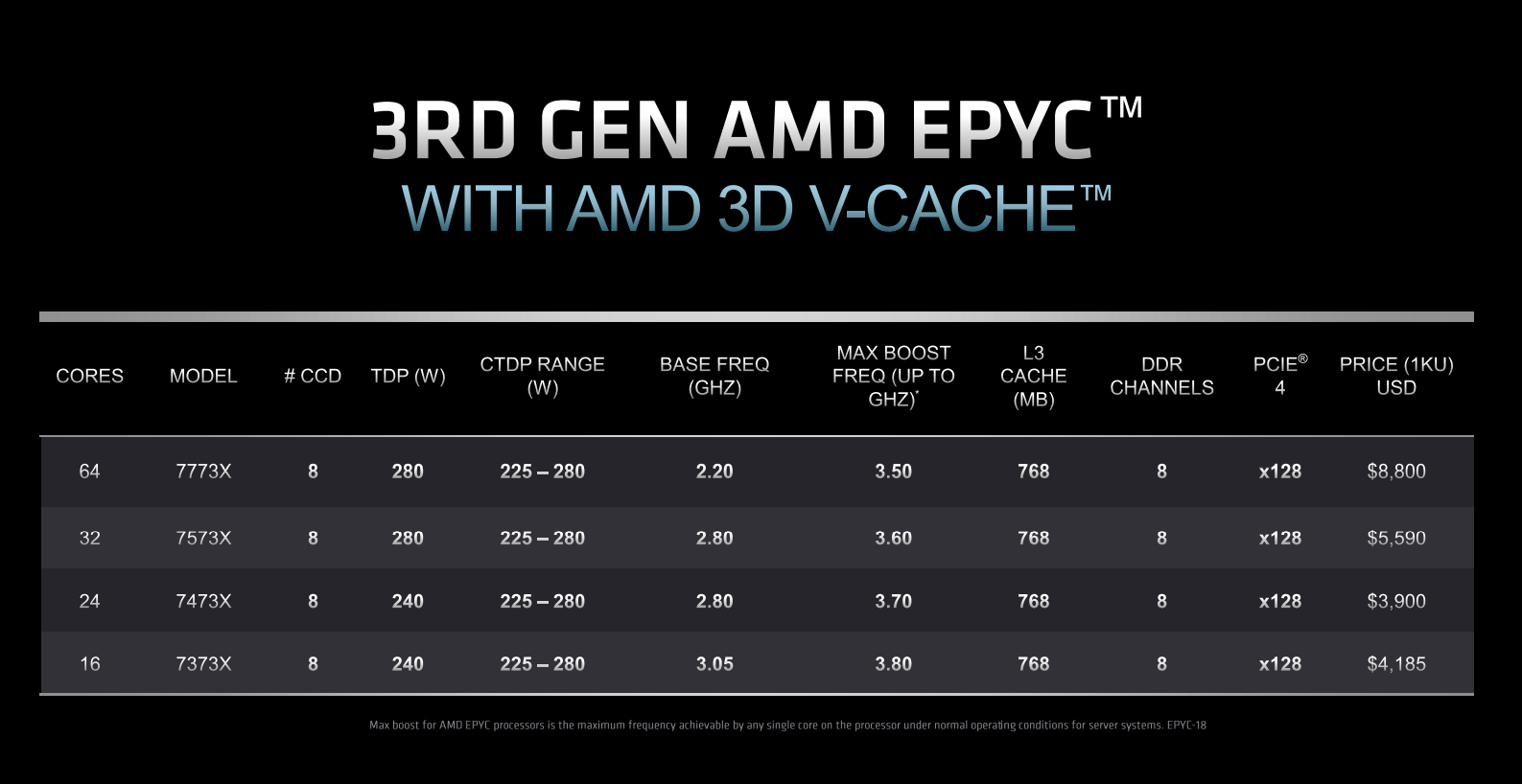
AMD officially releases four 3D V-Cache-equipped chips today. The quartet has an X suffix denoting tripling of L3 and, interestingly, all are hewn from best-in-class 8-CCD setups, leading to 768MB for all. The 16-core 7373X, for example, has only two cores active in each 8-core-capable CCD, the 24-core has three, and so on.
Milan-X is organised this way to maximise L3 per core, which is its raison d’etre. As an extreme example, 7373X’s two cores per CCD access 96MB L3, or 48MB apiece, though it doesn’t work this way as each core in a CCD has full reach of the entire 96MB. The ratio drops to 12MB-per core for 7773X, but that’s still impressive.
Compared to non-X solutions touting the same core configurations, 3D V-Cache chips are about 20 per cent more expensive. Power remains at about the same levels, too, as the extra juice required to drive an additional 512MB L3 is offset by greater cache hits, meaning less need to power external DDR4 memory as often.
It’s curious the 16-core 7373X is more expensive than 24-core 7473X – the same is true when comparing non-X 73F3 (16C32T) to 7473 (24C48T). This may have to do with applications licensed on a per-core basis, and AMD knows it can charge more when used with software that tops out at 16 cores.


Installing Milan-X into existing Epyc Milan-supporting boards is a simple matter of a BIOS update. Largest performance gains for cache-heavy chips come in EDA, CFD, finite element and structural analysis workloads, says AMD.
The company is reticent in comparing Milan X to regular Milan save for one benchmark, where Milan-X is 66 per cent faster than same-core Milan in RTL verification. Performance uplift mileage varies considerably by application, and large-scale customers will have had Milan-X in testing for a while, knowing exactly how it compares to regular Milan for their use cases.

The Wrap
Compared on a core-for-core basis against Intel Xeon Platinum (Ice Lake), AMD picks cache-sensitive benchmarks that it does ever so well in. Industry watchers know Intel is set to release next-generation Sapphire Rapids Xeons soon, so the above comparo will be out of date in short order. Nevertheless, we expect AMD to hold on to a like-for-like lead in many applications.
Designed to fit neatly inside on-prem server clusters where workload scaling is near-linear and sensitive to cache levels, Milan-X makes sense for a small but volume-rich portion of server customers. Most others will make do just fine with incumbent Milan, especially if workloads are more compute bound, and will likely wait until Zen 4-based Genoa makes waves later this year.
Serving as the vanguard processor in vertically stacking oodles of extra L3 cache for significant workload-specific gains, realising up to 1.5GB per 2P board, AMD Epyc Milan-X is an able proof of concept.